Lasso
Contents
Lasso#
Lasso Regression is the name of the regression task employing an \(L_1\)-regularization term. Among the \(L_p\) norms, the \(L_1\) norm is the closest convex alternative to \(L_0\). In contrast to the \(L_2\) norm, which penalizes larger values more strongly due to its quadratic growth, the \(L_1\) norm grows linearly and thus resembles the counting behavior of \(L_0\) more closely. At the same time, the \(L_1\) norm is not as well-behaved from an optimization perspective as the squared \(L_2\) norm. While it is convex and continuous, it is not differentiable at zero, which makes optimization more involved than in the \(L_2\) case.
Task (Lasso Regression)
Given a dataset of \(n\) observations
the design matrix \(X\in\mathbb{R}^{n\times p}\), where \(X_{i\cdot}=\bm\phi(\vvec{x}_i)^\top\) and a regularization weight \(\lambda>0\).
Find the regression vector \(\bm\beta\), solving the following objective
Return the predictor function \(f:\mathbb{R}^d\rightarrow\mathbb{R}\), \(f(\vvec{x})=\bm\phi(\vvec{x})^\top\bm\beta\).
The drawback of using a \(L_1\)-regularization term is that the resulting objective function in Eq. (25) is not differentiable if any value of \(\beta\) is zero. However, we can generalize from the concept of a gradient to a subgradient, and the subgradient of the \(L_1\)-norm is given as follows:
We observe that the subgradient returns a set of values where \(\beta_k=0\). Minimizers of objective functions which have a subgradient satisfy \(\vvec{0}\in\nabla f(\vvec{x})\) (FONC for subgradients).
Optimization#
The FONC for subgradients would allow us in principle to find again the stationary points, that are also the minimizers of the Lasso task, because the Lasso objective is convex. Unfortunately, solving for the stationary points of the subgradient \(\nabla RSS_{L_1}(\bm\beta)=0\) is too complicated (feel free to try it yourself). Yet, the function is simple enough to do the next best thing, which is coordinate descent. We derive the minimizers subject to one coordinate as stated in the following theorem.
Theorem 17 (Coordinate-wise Lasso Minimizers)
The minimizer of Lasso subject to the coordinate \(\beta_k\)
Proof. FONC for subgradients \(\vvec{0}\in \frac{\partial }{\partial \beta_k}RSS_{L_1}\) yields the solutions to the coordinate-wise minimization problems.
We compute the stationary points and set \(\frac{\partial}{\partial \beta_k} RSS_{L1}(\beta)=0\):
We have now a characterization of the minimizers of \(\beta_k\) in dependence of the partial derivative of the \(L_1\) norm. The term \(c_k\) does not depend on the coordinate that we want to optimize, hence we can consider this term as a constant. The partial derivative depends on three cases: \(\beta_k>0, \beta_k<0\) and \(\beta_k=0\). We have a look at these cases now.
case 1: \(\beta_k>0\)
If \(\beta_k>0\), then the partial derivative is equal to \(\frac{\partial\lvert\beta\rvert}{\partial \beta_k}=1\). That is, we have:
Therewith we obtain the result that \(\beta_k = \frac{1}{\lVert X_{\cdot k}\rVert^2}\left(c_k - \frac \lambda 2\right)\) if \(c_k>\frac \lambda 2\).
case 2: \(\beta_k<0\)
We follow the same steps as above. If \(\beta_k<0\), then the partial derivative is equal to \(\frac{\partial\lvert\beta\rvert}{\partial \beta_k}=-1\), yielding:
As a result, \(\beta_k = \frac{1}{\lVert X_{\cdot k}\rVert^2}\left(c_k + \frac \lambda 2\right)\) if \(c_k<-\frac \lambda 2\).
case 3: \(\beta_k=0\)
If \(\beta_k=0\), then the partial derivative is in the interval \(\frac{\partial\lvert\beta\rvert}{\partial \beta_k}\in [-1,1]\). Let’s say we have a parameter \(\alpha\in[-1,1]\), then
As a result, we have \(\beta_k=0\) and \(c_k\in[-\frac \lambda 2,\frac \lambda 2]\).
Given these coordinate-wise minimizers for the Lasso objective, we can formulate the Lasso algorithm as follows.
Algorithm 6 (Lasso)
Input: \(X,y,\lambda\)
\(\bm\beta\gets\)
Initialize(\(p\))while not converged
for \(k\in\{1,\ldots, p\}\)
\(c_k\gets X_{\cdot k}^\top (\vvec{y}- \sum_{i\neq k} X_{\cdot i}\beta_i)\)
\(\beta_k\gets \begin{cases} \frac{1}{\lVert X_{\cdot k}\rVert^2}(c_k -\frac\lambda 2) & \text{if } c_k>\frac \lambda 2\\ \frac{1}{\lVert X_{\cdot k}\rVert^2}(c_k +\frac\lambda 2) & \text{if } c_k<-\frac \lambda 2\\ 0 & \text{if } -\frac\lambda 2\leq c_k\leq \frac\lambda 2\end{cases}\)
return \(\bm\beta\)
We can already see from the update rules that Lasso is more likely than Ridge Regression to perform feature selection, and to set some of the coordinates of \(\bm\beta\) to zero. If a coordinate \(\beta_k\) is in absolute values no larger than the regularization weight \(\lambda\), then the coordinate is set to zero. Hence, the very small values (in absolute terms) observed from Ridge Regression can’t happen for Lasso. The values of the Lasso regression vector \(\bm\beta\) are either zero or at least as large as \(\lambda\).
Example#
We use again the data from Example 16, but now we apply Lasso with varying regularization weights.
import numpy as np
D = np.array([5,3,1])
y = np.array([2,5,3])
We implement the Lasso method for a given design matrix \(X\), target vector \(\vvec{y}\), regularization weight \(\lambda\) and a fixed number of coordinate descent steps \(t_{max}\). As discussed in the context of Ridge Regression, we also do not apply the penalization for the intercept in the Lasso optimization scheme.
def β_lasso(X,y,λ, t_max=1000, intercept_id=0):
p=X.shape[1]
β = np.random.rand(p)
for t in range(t_max):
for k in range(p):
c_k = X[:,k].T@(y-X@β +X[:,k]*β[k])
if k== intercept_id:
β[k] = c_k
else:
β[k] = np.sign(c_k)*np.maximum((np.abs(c_k)-λ/2),0)
β[k] = β[k]/np.linalg.norm(X[:,k])**2
return β
Now, we compute the Lasso regression functions for a centered target vector (as discussed in the previous section) and with varying regularization weights.
import matplotlib.pyplot as plt
def ϕ(x):
return np.row_stack((np.ones(x.shape[0]),x, x**2, x**3))
X=ϕ(D).T
plt.figure(figsize=(10, 7))
x = np.linspace(0, 6, 100)
for λ in [0.001,1,10, 100, 1000]:
β = β_lasso(X, y, λ, t_max=3000)
f_x = ϕ(x).T@β
plt.plot(x, f_x, label="f_"+str(λ))
plt.scatter(D, y, edgecolor='b', s=50)
plt.xlabel("x")
plt.ylabel("y")
plt.ylim((-5, 15))
plt.axhline(0, linewidth=0.5, linestyle='--', color='gray') # horizontal lines
plt.axvline(0, linewidth=0.5, linestyle='--', color='gray') # vertical lines
plt.legend(loc="best")
plt.show()
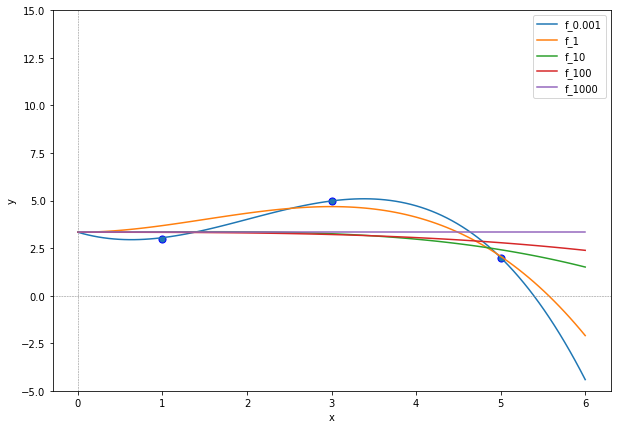
If we compare these plots to the ones of Ridge Regression, then we observe that the regularization weight of Lasso has a bigger influence on the regression functions. For \(\lambda\geq 10\), we obtain very flat approximations, whose graph does not decrease so rapidly for \(x\rightarrow \infty\) as for \(\lambda\leq 1\). This effect is supported by the regression vector values, indicated below.
for λ in [0.001,1,10, 100, 1000]:
β = β_lasso(X, y, λ)
print(λ,"\t",np.round(β,4))
0.001 [ 0.0619 3.5971 -0.6631 0.0042]
1 [ 2.5952 0.3791 0.3972 -0.0987]
10 [ 4.0311 0. 0. -0.0137]
100 [ 3.7627 0. -0. -0.0084]
1000 [ 3.3333 -0. -0. -0. ]
Already for \(\lambda=1\) the first feature of the design matrix is deemed irrelevant for the Lasso regression task. For \(\lambda=100\) only one of the three features and the intercept are still used and for \(\lambda=1000\) we obtain a constant regression function.