MLPs
Contents
MLPs#
Neural networks get their name from their loose inspiration of connections between neurons in the brain and how the brain learns by strengthening these connections. While the mechanisms that enable a human brain to capture complex patterns are vastly different to how neural networks are designed, neural networks still borrow loads of their terminology from the description of the brain. One such example is the neuron that is in the name of neural networks.
An Artificial Neuron#
The artificial neuron is supposed to simulate the firing process of an actual neuron. Given an input vector \(\vvec{x}\), the artificial neuron computes a (typically nonnegative) output based on an affine function and a nonlinear activation function \(\phi_a\). Graphically, this is typically presented like this:

The input is inserted into the neuron and a weighted sum of the input with the coefficients of the vector \(\vvec{w}\) is symbolized by the directed edges from the input nodes to the output node. We can imagine that every edge from node \(k\) has edge weight \(w_k\), which is multiplied with the input \(x_k\), returning \(w_kx_k\) at the end of each single edge. All the edges are summed up, yielding \(\sum_k w_kx_k\).
Within the output node, we add a bias term and apply the activation function \(\phi_a\). In the beginning, the sigmoid function has been used as an activation function, since it has this nice interpretation as a soft thresholding function that simulates the firing or not firing status of a neuron. However, the sigmoid function suffers from optimization issues, which is why other activations became more popular. We discuss this later.
In summary, a neuron computes the following function:
Note
Any affine function in \(d\) dimensions can be written as a linear function in \(d+1\) dimensions (as we also did it for the application of linear regression for learning affine functions). That is, we absorb the bias into the weights by specifying \( w_{0} = b \) and creating a new dummy input \( x_{0} = 1 \). This way we can write an affine function as a linear function.
Because of this notational possibility, we speak in machine learning often of a linear function although we technically mean an affine function. This happens in particular in the neural networks terminology.
From Neuron to Layer#
We can stack now multiple neurons into a layer. The plot below shows the input being transformed into a \(d_1\)-dimensional space by \(d_1\) neurons. Each neuron computes an affine function \(\vvec{w}_j^\top\vvec{x}+b_j\) followed by an activation function \(\phi_a\).

Gathering all the weight vectors \(\vvec{w}_j\) in a matrix \(W\in\mathbb{R}^{d_1\times d}\), such that \(W_{j\cdot} = \vvec{w}_j^\top\) and the bias terms in vector \(\vvec{b}\in\mathbb{R}^{d_1}\), we can write the output vector generated by one layer as
Note
A layer that models an activation function applied to an affine function as discussed above is usually referred to as a linear layer (because of the rather technical distinction between affine and linear functions noted above) or a dense layer, or a fully connected layer.
From one Layer to the Multi-Layer Perceptron#
A Multi-Layer Perceptron (MLP), a.k.a. feed forward neural network stacks multiple layers after each other, where each layer is an affine function followed by an activation function. The purpose of a hidden layer is to transform the representation of the data into a new feature space in which the following layer can more easily separate or process the data. The plot below shows an MLP with one input layer (left), a hidden layer (middle) and an output layer (right).

The output function is computed layer by layer, that is the output vector \(\vvec{z}\) is computed as
Likewise, we can add another layer and get a MLP with four layers:

Now, the output is the composition of three functions that are computed by each layer:
Note that each layer can have its own dimensionality. This is often difficult to depict visually, but we can either expand or decrease the dimensionality in each layer.
Activation Functions#
Each layer stacks an affine function with a nonlinear activation function. The nonlinearlity of the activation functions prevent that the stacked layers collapse to a single affine function. That is because the composition of affine functions is an affine function itself. Assume we don’t use a nonlinear activation function after the first hidden layer, then the first two layers collapse to one linear layer:
where \(\tilde{W} = W^{(2)}W^{(1)}\) and \(\tilde{\vvec{b}} = W^{(2)}\vvec{b}^{(1)} + \vvec{b}^{(2)}\). Applying a nonlinear function after each affine function prevents the layers from collapsing to a simple affine function and allows the network to learn complex functions by stacking simple layers after each other.
Sigmoid and Tanh#
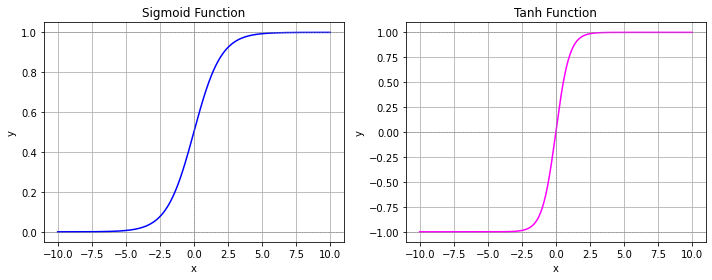
The sigmoid function has been used as an activation function back in the days, since it gives a nice interpretation of a neuron firing (sigmoid being close to one) or not (sigmoid being close to zero). The sigmoid function is defined as
Similar to the sigmoid function is the \(\tanh\) function, mapping real values to the range of \([-1,1]\) in contrast to sigmoid having as range \([0,1]\).
However, the sigmoid and tanh functions are not easy to optimize in a hidden layer, since they suffer from the vanishing gradient problem. If you look at the plot below, then you see that the derivative at points on the left and the right is close to zero. As a result, sigmoid and tanh are used less frequently in hidden layers of modern deep networks. Using them in the last layer is suitable because the logarithmic loss function counteracts the vanishing gradient problem.
import numpy as np
import matplotlib.pyplot as plt
# Define activation functions
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def tanh(x):
return np.tanh(x)
# Create input range
x = np.linspace(-10, 10, 500)
y_sigmoid = sigmoid(x)
y_tanh = tanh(x)
# Create side-by-side plots
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))
# Plot sigmoid
ax1.plot(x, y_sigmoid, color="blue")
ax1.set_title("Sigmoid Function")
ax1.axhline(0, color='gray', linestyle='--', linewidth=0.5)
ax1.axhline(1, color='gray', linestyle='--', linewidth=0.5)
ax1.axvline(0, color='gray', linestyle='--', linewidth=0.5)
ax1.grid(True)
ax1.set_xlabel("x")
ax1.set_ylabel("y")
# Plot tanh
ax2.plot(x, y_tanh, color="magenta")
ax2.set_title("Tanh Function")
ax2.axhline(0, color='gray', linestyle='--', linewidth=0.5)
ax2.axhline(1, color='gray', linestyle='--', linewidth=0.5)
ax2.axhline(-1, color='gray', linestyle='--', linewidth=0.5)
ax2.axvline(0, color='gray', linestyle='--', linewidth=0.5)
ax2.grid(True)
ax2.set_xlabel("x")
ax2.set_ylabel("y")
plt.tight_layout()
plt.show()
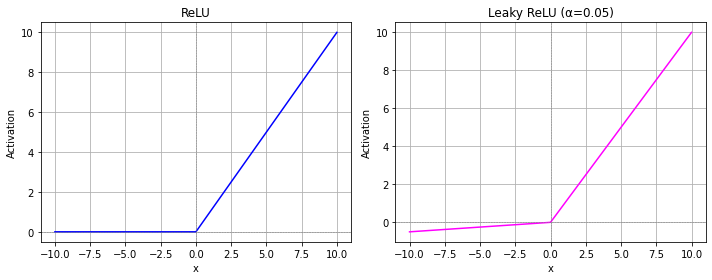
ReLU and Leaky ReLU#
The Rectified Linear Unit (ReLU) is a currently very popular activation function. It is defined as
import numpy as np
import matplotlib.pyplot as plt
# Define activation functions
def relu(x):
return np.maximum(0, x)
def leaky_relu(x, alpha=0.05):
return np.where(x > 0, x, alpha * x)
# Create input range
x = np.linspace(-10, 10, 500)
y_relu = relu(x)
y_leaky_relu = leaky_relu(x)
# Create side-by-side plots
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))
# Plot ReLU
ax1.plot(x, y_relu, color="blue")
ax1.set_title("ReLU")
ax1.axhline(0, color='gray', linewidth=0.5, linestyle='--')
ax1.axvline(0, color='gray', linewidth=0.5, linestyle='--')
ax1.grid(True)
# Plot Leaky ReLU
ax2.plot(x, y_leaky_relu, color="magenta")
ax2.set_title("Leaky ReLU (α=0.05)")
ax2.axhline(0, color='gray', linewidth=0.5, linestyle='--')
ax2.axvline(0, color='gray', linewidth=0.5, linestyle='--')
ax2.grid(True)
# Common settings
for ax in (ax1, ax2):
ax.set_xlabel("x")
ax.set_ylabel("Activation")
plt.tight_layout()
plt.show()
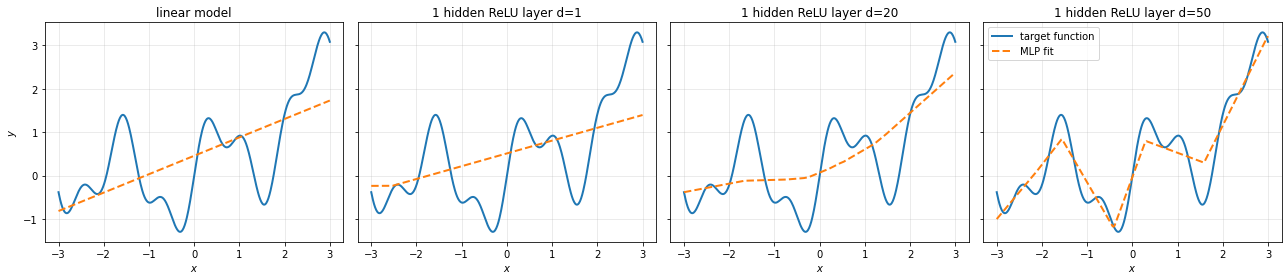
MLPs are Universal Function Approximators#
One of the foundational theoretical results for neural networks is the Universal Approximation Theorem. This theorem formalizes the power of neural networks: a sufficiently large neural network can approximate any reasonable function to arbitrary accuracy.
A network can be large in terms of its width, the dimensionality of the hidden layers, or its depth, the amount of stacked layers. Below you see how a simple MLP with one hidden layer and ReLU activation can be used to approximate a rather complex function. From the left to the right, the fit of the function approximation increases as we increase the dimensionality of the hidden layer. We can also see in the plot how ReLU networks generate piecewise linear functions, where each neuron introduces additional bends or transitions in the learned function.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
# target function
def f(x):
return (
np.sin(3 * x)
+ 0.5 * np.sin(7 * x)
+ 0.3 * x
+ 0.15 * x**2
)
# data
rng = np.random.default_rng(42)
X = np.linspace(-3, 3, 120).reshape(-1, 1)
y = f(X[:, 0]) #+ rng.normal(0, 0.15, size=X.shape[0])
X_plot = np.linspace(-3, 3, 500).reshape(-1, 1)
y_true = f(X_plot[:, 0])
# models: same width, increasing depth
models = {
"linear model": None,
"1 hidden ReLU layer d=1": (1,),
"1 hidden ReLU layer d=20": (20,),
"1 hidden ReLU layer d=50": (50),
}
fig, axes = plt.subplots(1, 4, figsize=(18, 4), sharey=True)
for ax, (title, hidden_layers) in zip(axes, models.items()):
if hidden_layers is None:
# MLP with no hidden layer is just a linear model
from sklearn.linear_model import LinearRegression
model = make_pipeline(StandardScaler(), LinearRegression())
else:
model = make_pipeline(
StandardScaler(),
MLPRegressor(
hidden_layer_sizes=hidden_layers,
activation="relu",
max_iter=5000,
alpha=1e-4,
random_state=42,
)
)
model.fit(X, y)
y_pred = model.predict(X_plot)
#ax.scatter(X[:, 0], y, s=20, alpha=0.5, label="training data")
ax.plot(X_plot[:, 0], y_true, linewidth=2, label="target function")
ax.plot(X_plot[:, 0], y_pred, linewidth=2, linestyle="--", label="MLP fit")
ax.set_title(title)
ax.set_xlabel("$x$")
ax.grid(True, alpha=0.3)
axes[0].set_ylabel("$y$")
axes[-1].legend(loc="best")
plt.tight_layout()
plt.show()
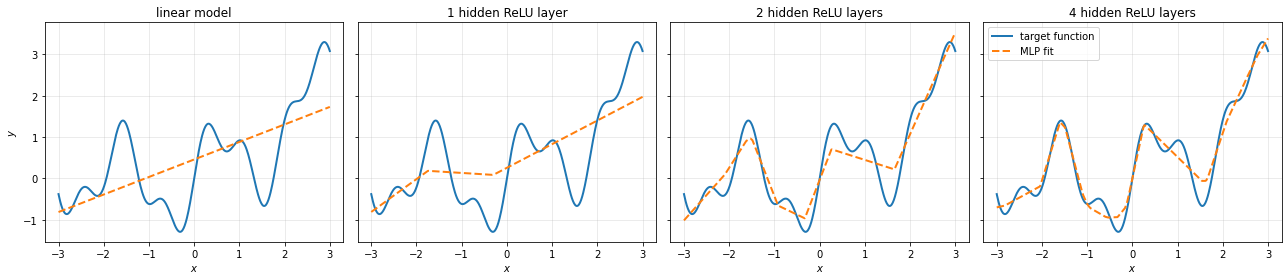
The plot below illustrates how we can reflect complex function shapes over increasing the depth of the network. We stack hidden layers of dimension \(d_l=10\). As we increase the number of hidden layers, the network learns increasingly flexible representations and can approximate the target function more accurately.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
# target function
def f(x):
return (
np.sin(3 * x)
+ 0.5 * np.sin(7 * x)
+ 0.3 * x
+ 0.15 * x**2
)
# data
rng = np.random.default_rng(42)
#X = np.linspace(-3, 3, 120).reshape(-1, 1)
#y = f(X[:, 0]) #+ rng.normal(0, 0.15, size=X.shape[0])
X_plot = np.linspace(-3, 3, 500).reshape(-1, 1)
y_true = f(X_plot[:, 0])
# models: same width, increasing depth
models = {
"linear model": None,
"1 hidden ReLU layer": (10,),
"2 hidden ReLU layers": (10, 10),
"4 hidden ReLU layers": (10, 10, 10, 10),
}
fig, axes = plt.subplots(1, 4, figsize=(18, 4), sharey=True)
for ax, (title, hidden_layers) in zip(axes, models.items()):
if hidden_layers is None:
# MLP with no hidden layer is just a linear model
from sklearn.linear_model import LinearRegression
model = make_pipeline(StandardScaler(), LinearRegression())
else:
model = make_pipeline(
StandardScaler(),
MLPRegressor(
hidden_layer_sizes=hidden_layers,
activation="relu",
max_iter=5000,
alpha=1e-4,
random_state=42,
)
)
model.fit(X, y)
y_pred = model.predict(X_plot)
#ax.scatter(X[:, 0], y, s=20, alpha=0.5, label="training data")
ax.plot(X_plot[:, 0], y_true, linewidth=2, label="target function")
ax.plot(X_plot[:, 0], y_pred, linewidth=2, linestyle="--", label="MLP fit")
ax.set_title(title)
ax.set_xlabel("$x$")
ax.grid(True, alpha=0.3)
axes[0].set_ylabel("$y$")
axes[-1].legend(loc="best")
plt.tight_layout()
plt.show()
Theoretically, we can prove that a single hidden layer network is sufficient to approximate any continuous function. The following theorem is a popular variant of a series of universal approximation theorems, stating that a feedforward neural network (MLP) with at least one hidden layer and a suitable activation function (like the sigmoid or ReLU), can approximate any continuous function on a compact subset of \(\mathbb{R}^d\), given enough hidden units.
Theorem 26 (Universal Approximation Theorem)
Let \(f: \mathbb{R}^d \to \mathbb{R}\) be a continuous function, and let \(\epsilon > 0\). Then there exists a neural network (MLP) \(f_\theta\) with a single hidden layer with a ReLU, Leaky ReLU or sigmoid activation and a finite number of neurons such that:
for any compact set \(\mathcal{K} \subset \mathbb{R}^d\).
This means neural networks can get as close as we want to any target function in theory - with just a single hidden layer. We call networks that have just a single layer, that is typically very wide, a shallow network. However, the theorem and its variants are non-constructive: it tells us such a network exists but not how to find it. Still, the theorem motivates research in training neural networks to their full potential. In the context of machine learning, we are particularly interested in training the neural networks such that they learn useful and meaningful representations of the data.
In practice, deep neural networks, using many layers, are more efficiently trained and stored. Shallow neural networks often need a huge amount of neurons in their hidden layer to learn good representations. Stacking instead multiple lower dimensional layers after one another requires often fewer parameters to be trained.
MLPs with a Softmax Regression Classifier Head#
If we want to pursue specific machine learning tasks, such as classification, we can stack together a more general MLP, stacking linear layers, and a classification module, such as the softmax regression. For example, we can add a softmax regression module to the MLP with two hidden layers, obtaining the following structure:

Defining a Classifier MLP in Pytorch#
Pytorch is an open source deep learning framework that allows for a flexible definition of MLPs and its optimization. Any neural network, such as our MLP from above, can be implemented as a subclass of torch.nn.Module. For classification, the neural network is expected to output the logits (the output before softmax) instead of the softmax probabilities, because the softmax is integrated in the computation of the loss functions.
To define a network, we initialize the layers in the __init__ function. An affine layer mapping from a \(5\)-dimensional layer to a \(10\)-dimensional layer is defined as nn.Linear(5,10). The example below implements a two-hidden-layer network and shows the output (the logits) for five randomly generated data points.
import torch
import torch.nn as nn
# Two hidden layers: input -> hidden -> 2D latent -> output
class TwoHiddenLayerNet(nn.Module):
def __init__(self, input_dim=10, num_classes=2):
super().__init__()
self.hidden1 = nn.Linear(input_dim, 128)
self.hidden2 = nn.Linear(128, 64)
self.output = nn.Linear(64, num_classes)
def forward(self, x):
x = torch.relu(self.hidden1(x))
x = torch.relu(self.hidden2(x))
return self.output(x)
model = TwoHiddenLayerNet(input_dim=10, num_classes=3)
# Create dummy input: batch of 5 samples, each with 10 features
x = torch.randn(5, 10)
# Forward pass
logits = model(x)
# Output
print("Logits:", logits)
Logits: tensor([[ 0.0291, 0.0481, 0.1319],
[ 0.1440, 0.0606, 0.0421],
[ 0.0593, -0.0225, 0.1104],
[ 0.0663, -0.0512, 0.0683],
[ 0.1370, 0.0256, 0.0808]], grad_fn=<AddmmBackward0>)
We see that the output has an additional variable called grad_fn. This variable stores information that is necessary to compute the gradient of the network subject to the weights in the hidden layers. How we are going to compute that, we will see in the next section.