Evaluation
Contents
Evaluation#
Bias Variance Tradeoff#
Similar to the Bias-Variance Tradeoff in Regression, we can formulate the bias-variance tradeoff for classification.
Theorem 25 (bias-variance tradeoff for classification)
Gievn an observation \(\mathbf{x}_0\) with label \(y\) and ground truth label \(y^*\). Let \(\hat{y}_\mathcal{D}\) denote the classifier of a given model class, that has been trained on the dataset \(\mathcal{D}\), and denote with
where
Just like in regression, we decompose the EPE into three parts: a noise, a bias and a variance term. The noise part is again inherent to the data and not dependent on the model. In classification, the noise describes how many labels are wrong in the dataset.
Corollary 4
The classification noise random variable is equal to the probability that the label is not equal to the true label
Proof. According to the definition of the expected value of a random variable with finitely many outcomes
The bias describes how far the predictions are from the true label when we aggregate the results over various classifiers. In regression, the aggregated regression model computed the mean over all regression models, in classification, the aggregated classifier predicts the majority vote of all classifiers. Lastly, the variance term describes the variance among the classifiers. Here, this is measured by the expected disagreement of the majority vote classifier and the indivdual classifiers.
Fig. 7 plots the result of a simulation of the bias-variance computation. Given a set of training data sets \(\mathcal{D}_1,\ldots \mathcal{D}_m\), we train one model on each training data set for varying levels of complexity. Each thin blue curve tracks how the prediction error changes when we vary the complexity of the model, while training on the same dataset. That is, we have as many blue curves as there are training data sets. The thick blue line represents the mean of the thin blue lines. The red curves track the prediction error on the test set and the thick red line averages the thin red lines. We can see how the models tend to overfit with increasing complexity, because they have a low training error but an increasing test error. The increase in the variance of the models increases the test error. For a low model complexity, the test error is largely increased by the training error, which indicates a high bias.
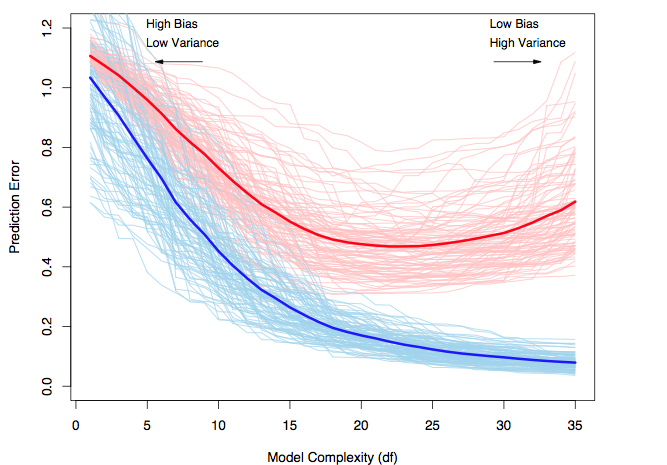
Fig. 7 The prediction error as a function of model complexity (borrowed from [2]). Blue indicates performance on the training data and red indicates performance on the test data. Each thin line corresponds to one dataset.#
Whether a classifier overfits or underfits depends on the model choice and their hyperparameters. For example, a linear classifier is not a good model choice for a nonlinear classification problem, or naive Bayes is not a good model choice if the features correlate. The table below lists the key parameters of our considered classifiers and how they influence over- and underfitting.
Classifier |
Key Hyperparameter(s) |
Description |
Effect on Under/Overfitting |
|---|---|---|---|
k-NN |
|
Number of neighbors considered for classification |
Small |
Naive Bayes |
|
Laplace smoothing variable |
large values flatten the probabilities → increases NB tendency to underfit |
Decision Tree |
|
Maximum depth of the tree |
Large depth → overfitting; small depth → underfitting |
|
Minimum samples to split or keep as leaf |
Larger values → less overfitting |
|
Random Forest |
|
Number of trees in the ensemble |
Too few → overfitting; more trees → lower variance |
|
Features considered per split |
Lower → more diversity, less overfitting |
|
SVM |
|
Regularization strength: margin softness |
Large |
|
Type of transformation (e.g., |
Complex kernels → higher risk of overfitting |
|
|
Controls influence of single training examples |
High |
Typical Classification workflow#
The evaluation in classification has two purposes: finding the best hyperparameters for a model (tuning) and to assess the fit of the model (assessing overfitting and underfitting). Doing both, requires a nested evaluation and training technique, which is detailed in Fig. 8. The training procedure in the Repeat rectangle is used to tune the hyperparameters. The test error is computed for the model with the best validation error.
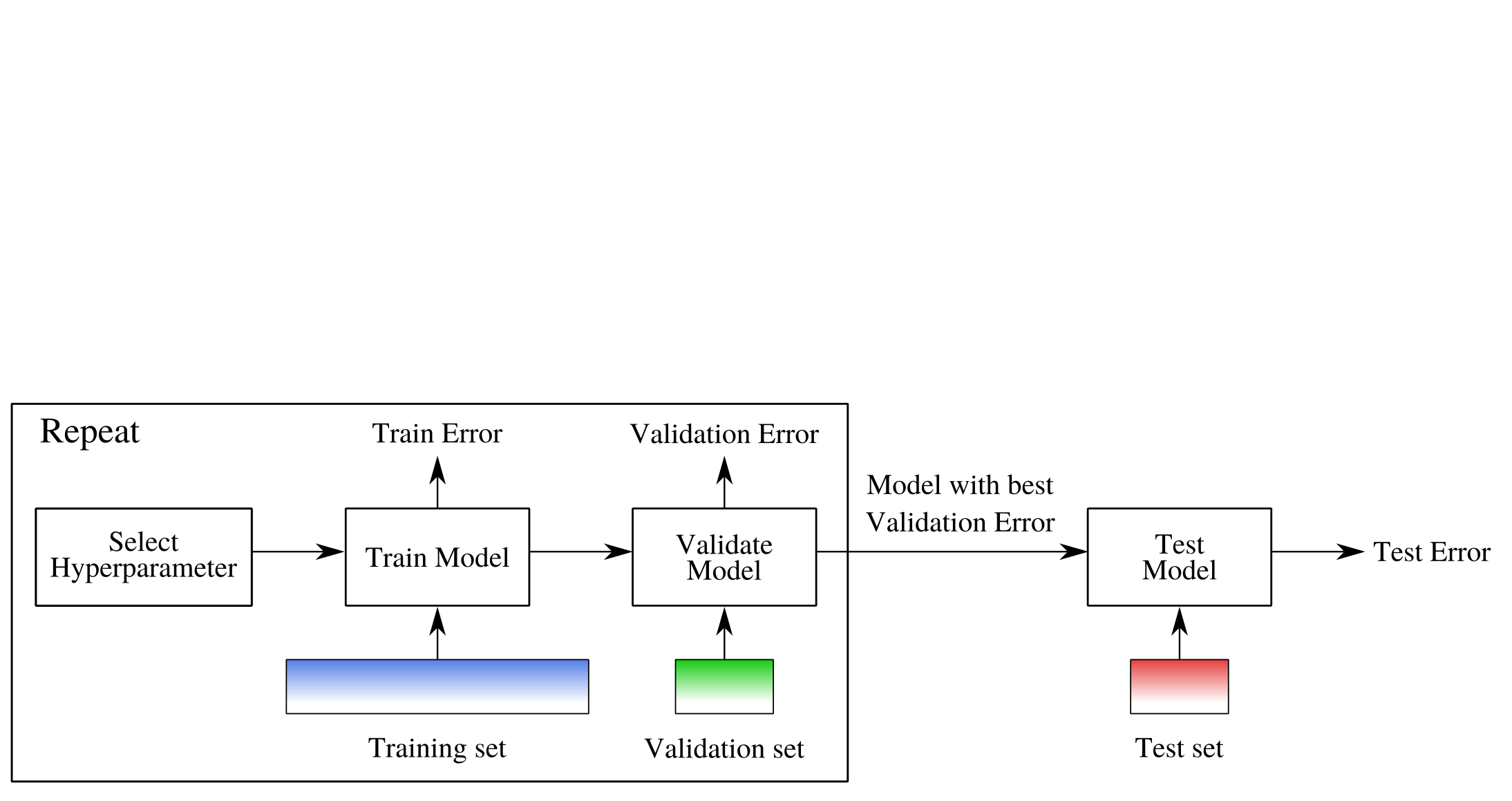
Fig. 8 A block diagram representing a typical ML workflow.#
In the graphic, a train/validation/test split is used:
Training set: used to fit the model.
Validation set: used to tune hyperparameters and make model selection decisions.
Test set: used only once for final model evaluation.
This approach may be sensitive to the choice of the specific validation and test set, but if we have large data and/or classifiers that take a long time to train, this is a valid approach.

However, we can of course also perform cross validation, as we have already discussed it for regression (averaging an evaluation metric instead of the MSE). Whether we should use cross validation instead of a simple split, largely depends on whether we can afford it, based on training time and size of the dataset.
In classification, we often use stratified k-fold cross-validation to preserve the class distribution in each fold. This is particularly important for imbalanced datasets.
Warning
Avoid the human-in-the-loop Do not adjust the model parameters or hyper-parameters by guessing based on the testing accuracy / error. Do not allow the information containing in the testing data set leak to the training procedure.

Evaluation Metrics#
Straightforward evaluation metrics are the \(L_{01}\)-loss and the accuracy, that put into relation how many errors/correct predictions a classifier makes in a dataset. Given a classifier \(\hat{y}(\vvec{x})\), the accuracy of the classifier on dataset \(\mathcal{D}\) containing \(n\) data points is given as
The accuracy is a very simple metric that is often used because it’s easy to understand. However, it may be misleading when classes are imbalanced.
For example, consider a binary classification problem, where we have 950 data points belonging to class 1 and 50 data points belonging to class 2. If our classifier always predicts class 1, that is if it didn’t learn anything, the accuracy is still 0.95, which is quite high. To take special cases of datasets and their evaluation into account, various evaluation metrics have been proposed.
Confusion Matrix#
The confusion matrix provides a visualizable overview of the performance of a classifier by considering all outcomes of the true label vs. the predicted label. Assuming that we have a binary classification problem with a positive and a negative class, the confusion matrix returns the following table:
Predicted Positive |
Predicted Negative |
|
|---|---|---|
Actual Positive |
True Positive (TP) |
False Negative (FN) |
Actual Negative |
False Positive (FP) |
True Negative (TN) |
In the general case where we have \(c\) classes, the confusion matrix \(C\) is a \(c\times c\) matrix, where the entry \(C_{y,l}\) counts how many data points with label \(y\) are predicted to have label \(l\)
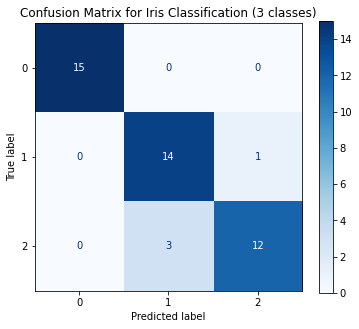
In the example below, we train a Gaussian Naive Bayes classifier on the Iris dataset, having three classes. The confusion matrix indicates that the first class is easy to distinguish from the other two classes, but the distinguishing between the other two classes is not too easy.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# Load the full Iris dataset (3 classes)
X, y = load_iris(return_X_y=True)
# Split into training and test sets (stratified to preserve class proportions)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# Train an SVM classifier
model = GaussianNB()
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Compute the confusion matrix
cm = confusion_matrix(y_test, y_pred)
# Display the confusion matrix
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=model.classes_)
fig, ax = plt.subplots(figsize=(6, 5))
disp.plot(ax=ax, cmap='Blues')
plt.title("Confusion Matrix for Iris Classification (3 classes)")
plt.show()
Precision, Recall, and F1-Score#
The confusion matrix shows on the diagonal the correct predictions and on the off-diagonal the errors of a classifier. In some applications, it matters what kind of error a classifier makes. For example, in the medical domain, it matters in cancer detection whether the classifier either fails to discover when a patient has cancer, or if the classifier discovers all cases of cancer but also sometimes predicts that a healthy patient has cancer. Having a false alarm is not as costly as a missed cancer diagnosis. In addition, knowing about the type of error that a classifier is susceptible to, helps in understanding when to trust the classifier and when we should take the prediction with a grain of salt. To that end, it makes sense to consider precision, recall and the F1-score:
Precision: \( \frac{TP}{TP + FP} = \frac{TP}{\text{Predicted Positive}}\) — how many predicted positives were correct.
Recall (Sensitivity): \( \frac{TP}{TP + FN} = \frac{TP}{\text{Actual Positive}}\) — how many actual positives were identified.
F1-Score: Harmonic mean of precision and recall:
In a multiclass scenario, the precision can be computed class-wise as estimators of the probability that the class is actually \(l\) if my classifier says so \(p(y=l\mid\hat{y}=l)\). Correspondingly, the recall returns the estimated probability that my classifier predicts class \(l\) if the actual class is actually \(l\).