Convolution
Contents
Convolution#
The universal approximation theorem states that we can in principle approximate any ground truth function. In practice, this is difficult. We have a powerful optimization method with SGD and momentum, but processing complex data types such as images was historically not really possible until convolution became a thing. Convolution stems from traditional image processing techniques over convolutional kernels (not similar to general kernel functions like the RBF kernels). Instead of defining specific kernels beforehand, convolutional layers allow a network to learn the kernels that fit the specific task and data.
2D Convolution#
Definition 45
Given a matrix \(X\in\mathbb{R}^{d_h\times d_w}\) representing for example an image. Let \(K\in\mathbb{R}^{k\times k}\) be the convolution kernel (filter). The output of a convolution is then defined as the matrix \(O\in\mathcal{R}^{d_h-k+1\times d_w-k+1}\) whose entries are given by
In a 2D convolution, a small kernel (also called a filter) is slid across the input image. The kernel acts like a template. At each location, an operation that can be expressed as an inner product between the flattened kernel and an image patch, measures how similar the local patch is to that template. This makes convolution useful for feature detection — each filter is tuned to respond to specific visual patterns (like edges, textures, corners).
The plot below visualizes the 2D convolution operation. The matrix on the left can be interpreted as the image, the matrix in the middle is the kernel and the matrix on the left is the output.
The images below visualize how a kernel acts as a filter of specific features. The kernel below has the form
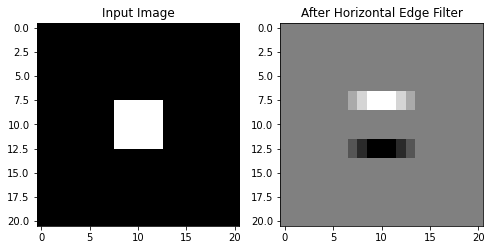
The images below show how this filter works on an actual image.
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from skimage import data, color
from PIL import Image
import torchvision.transforms as transforms
# Load astronaut image and convert to grayscale
astro_rgb = data.astronaut() # shape (H, W, 3)
astro_gray = color.rgb2gray(astro_rgb) # float64, shape (H, W), values in [0, 1]
# Convert to tensor and normalize
transform = transforms.Compose([
transforms.ToTensor(), # shape: (1, H, W)
])
astro_gray = astro_gray.astype('float32') # Convert to float32
image_tensor = torch.from_numpy(astro_gray).unsqueeze(0).unsqueeze(0) # shape (1, 1, H, W)
# Define horizontal edge-detection kernel
edge_filter = torch.tensor([[[[-1, -1, -1],
[ 0, 0, 0],
[ 1, 1, 1]]]], dtype=torch.float32)
# Create conv layer with custom filter
conv = nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv.weight.data = edge_filter
# Apply convolution
with torch.no_grad():
output = conv(image_tensor)
# Plot input and filtered output
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].imshow(image_tensor[0, 0], cmap='gray')
axes[0].set_title("Input: Astronaut (Grayscale)")
axes[0].axis('off')
axes[1].imshow(output[0, 0], cmap='gray')
axes[1].set_title("Output: Horizontal Edges")
axes[1].axis('off')
plt.tight_layout()
plt.show()

Stride and Padding#
The are two notable variants of the vanilla convolution approach: those that use padding and/or stride. These parameters control the spatial size of the output and the receptive field of the convolution.
The stride controls how much the kernel shifts at each step.
Stride = 1: standard behavior — the kernel moves one pixel at a time.
Stride > 1: the kernel moves in larger jumps — this downsamples the output.
Using a stride larger than one reduces spatial resolution. The example below shows a convolution with a stride of two.
Padding adds extra rows/columns around the input to the preserve the size of the input or control edge behavior.
Padding = 0: vanilla convolution, reduces the size of the output
Padding >0 : results in an output size of \(H-k + 2p+1\) (\(p\) is the padding size)
The example below shows a convolution with padding =1 and kernel of size \(3\times 3\) which preserves the size of the input.
The ouput size of a \((k\times k)\)-kernel with stride \(s\) and padding \(p\) is computed as:
We assume here that the stride and padding is applied symmetrically, to the width and the height of the input, but of course we can use in principle also varying padding and stride for each dimension.
Convolutional Layers#
In convolutional neural networks (CNNs), images are represented as 3D tensors. For a standard RGB image we have three channels (red, green, and blue). In general, we say that our input has \(C_{in}\) channels and width \(W\) and height \(H\). A 2D convolutional layer transforms a tensor into another tensor, where the dimensionality of the output tensor depends on the kernel size and additional parameters such as padding and stride.
Definition 46 (Convolution Layer)
A convolutional kernel takes an input tensor \(X\) of shape
The image below visualizes the shapes of an input tensor (left) and the output tensor of a convolutional layer (right). Note that one tensor in RGB channels represents one data point. The layer visualized below transforms a tensor with three channels to a tensor with four channels. Hence, this layer has four kernels of size \((C_{in},k,k)\) and four bias terms that are the weights of this layer.

Each channel of the output tensor is computed by computing \(C_{in}\) 2D convolutions, one for each input channel with its own 2D kernel, and then summing up the results. This procedure is visualized below with a three-channel input.
The output of a convolution is also called feature map. The idea is that each kernel learns a feature, like edges, texture or a shape, and each output channel of the convolution indicates where the learnt features can be found.
The images below visualize the feature maps of the first convolutional layers of the pretrained ResNet18 model for an astronaut input image.
import torch
import torchvision.models as models
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torchvision.models import resnet18, ResNet18_Weights
from PIL import Image
# Load a pretrained model
model = models.resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)
model.eval() # inference mode
# Choose a layer to visualize
layer_to_hook = model.conv1 # First conv layer
# Load and preprocess an image
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(), # shape: (3, H, W)
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
from skimage import data
from PIL import Image
import numpy as np
# Load the astronaut image and convert to PIL format
astronaut_np = data.astronaut() # shape: (H, W, 3), uint8
img = Image.fromarray(astronaut_np)
input_tensor = transform(img).unsqueeze(0) # shape: (1, 3, H, W)
# Hook to capture output of the layer
features = []
def hook_fn(module, input, output):
features.append(output.detach().squeeze(0)) # remove batch dim
handle = layer_to_hook.register_forward_hook(hook_fn)
# Forward pass
with torch.no_grad():
_ = model(input_tensor)
handle.remove()
# Plot feature maps
feature_maps = features[0] # shape: (C, H, W)
num_channels = feature_maps.shape[0]
# Plot the first N feature maps
N = 16
plt.figure(figsize=(12, 8))
for i in range(N):
plt.subplot(4, 4, i + 1)
plt.imshow(feature_maps[i].cpu(), cmap='viridis')
plt.title(f"Channel {i}")
plt.axis('off')
plt.tight_layout()
plt.show()
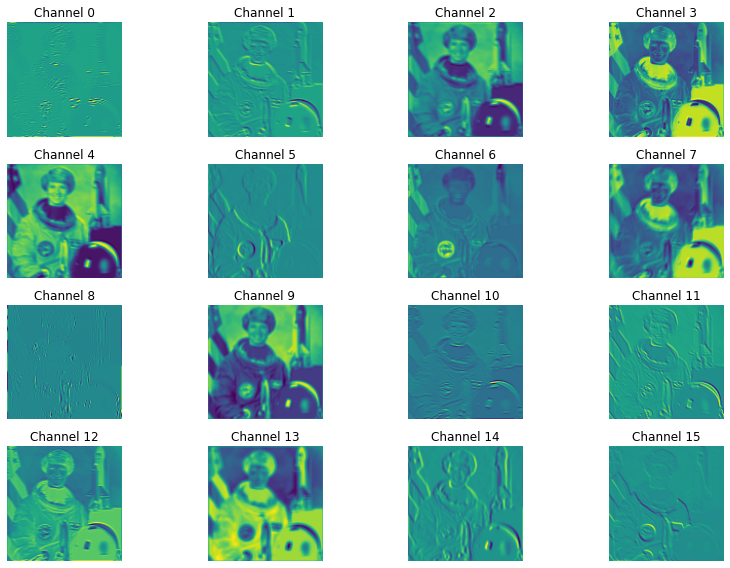
In Pytorch we use a convolutional layer as follows:
# Define a Conv2d layer:
# - 1 input channel
# - 1 output channel
# - 3x3 kernel
# - stride 1
# - no padding
conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=0, bias=True)
Training a Convolutional Layer#
In order to integrate a convolutional layer into the optimization scheme of neural networks by means of backpropagation, we need to derive the derivative of the convolution operation. Luckily, this is pretty simple, since convolutions are just linear functions after all. For example, consider the following convolution operation:
This convolution operation is equivalent to the following matrix multiplication:
This relationship helps us determining the Jacobian of a convolutional layer when we need to backpropagate through it. In this case, \(X\) is the output of the previous hidden layer and we have
Hence, by the chain rule, we compute for the Jacobian subject to a weight \(w\) that occurs in an earlier layer, as
The multiplication with \(A^\top\) is performing an operation on the inner derivative \(\frac{\partial \mathrm{vec}(X)}{\partial w} \) that is called transposed convolution. The transposed convolution is a convolution itself, which means that we don’t have to compute the massive matrix multiplication \(A\cdot\mathrm{vec}(X)\), that is required when representing convolution as a linear function, to compute the gradient.
If we want to compute the partial derivative subject to a kernel element, then we can better use the definition of the convolution. Here, we compute the partial derivative for the vanilla convolution with padding=0 and stride=1:
Inductive Bias#
If a convolution is just an affine function, what does it bring to use convolutional layers instead of fully connected ones? Every relationship that can be learned by a convolutional layer, can also be learned by an a dense one. The answer is that it can be very beneficial to restrict the parameter search space by applying assumptions about what kind of relationships we deem important for the task at hand. This introduces the topic of the inductive bias.
CNNs have very strong inductive biases, that are assumptions about how data should be processed and how it is structured. These assumptions made the accurate automatic processing of images with machine learning possible, and hence, the inductive bias of CNNs is a core topic in theory and practice. For example, the introduction of convolution meant that CNNs don’t need to learn from scratch that an edge is still an edge if it moves 10 pixels to the right.
Generally, an inductive bias is a built-in assumption that guides a learning algorithm toward certain types of solutions. It describes mainly design choices that push a model towards specific outputs that we deem more useful. For example, the assumption that a regression model only needs a subset of the available feature is an inductive bias in sparse regression models.
In convolutional neural networks (CNNs), the inductive biases are:
Locality: Nearby pixels form patterns that may be useful for the task.
Translation equivariance: If the input shifts, the output shifts accordingly (i.e., features are detected regardless of position).
Parameter sharing: The same filter (set of weights) is used across the whole image, reducing the number of parameters.
These assumptions make CNNs particularly effective for tasks with grid-structured data (e.g., images, video, audio spectrograms).