The Bias-Variance Tradeoff
Contents
The Bias-Variance Tradeoff#
In the previous subsection we have seen that the regression objective of minimizing the RSS has some reallly nice properties: we can determine the global optimum in an analytic way (by means of a formula). However, the initial goal of regression was to find the true feature-target relationship from the data. We want to find the true regression function. The question is now how we can evaluate our regression model towards our goal, when we don’t know what the true regression function is.
The regression task has some very well understood trade-off between bias and variance of a model. Bias and variance are here terms that are applied to a statistic estimator. To make these concepts more concrete, we have a look at a simple analogy.
Imagine repeatedly throwing darts at a dartboard, where the center of the board represents the true regression function \(f^*(x)\). Each throw corresponds to the prediction of a model \(f_\mathcal{D}\) trained on dataset \(\mathcal{D}\).
In this setting:
the average location of the darts corresponds to the expected prediction \(\mathbb{E}_\mathcal{D}[f_\mathcal{D}(x)]\),
the distance of this average from the center represents the bias, and
the spread of the darts around their average represents the variance.
This analogy allows us to visualize the effects of a bias, showing up as a consistent offset from the center, whereas variance shows up as a high, random fluctuations around their average location.
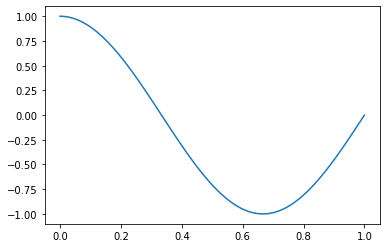
Evaluation on a Synthetic Dataset#
With this analogy in mind, we get started with the evaluation of the bias and variance of regression models by creating an example where we do know the true regression function. To do so, we generate a synthetic dataset from the function \(f^*(x) = \cos(1.5\pi x)\) (which we define as our true regression function) and some noise. We plot first our true regression function:
import numpy as np
import matplotlib.pyplot as plt
def f_true(x):
return np.cos(1.5 * np.pi * x)
x = np.linspace(0,1,100)
plt.plot(x,f_true(x))
plt.show()
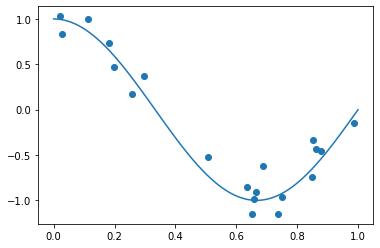
To create the synthetic dataset, we sample some data points from the interval \([0,1]\) and add some noise on the target values \(y= f^*(x)+\epsilon\). We sample the noise from a Gaussian normal distribution \(\epsilon\sim\mathcal{N}(0,\sigma)\).
np.random.seed(18) # set the seed of the random generator for reproducibility
n=20 # the number of data points
sigma = 0.15
D = np.random.uniform(0,1,n) # sample n data points from a uniform distribution
y = f_true(D) + np.random.normal(0,sigma,n)
x = np.linspace(0,1,100)
plt.plot(x,f_true(x))
plt.scatter(D,y) #plot the data points
plt.show()
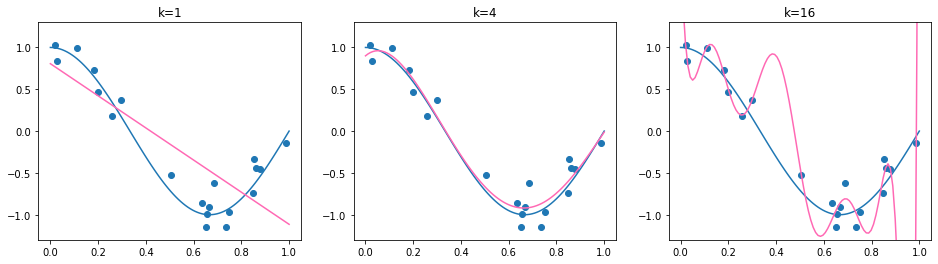
Now we have a synthetic dataset, given by the data matrix D and target vector y. We fit to this dataset polynomial functions of varying degrees \(k\in\{1,4,16\}\):
from sklearn.preprocessing import PolynomialFeatures
plt.figure(figsize=(16, 4))
p = 1
for k in [1,4,16]:
plt.subplot(1, 3 , p)
poly = PolynomialFeatures(k)
X = poly.fit_transform(D.reshape(-1, 1)) #design matrix for polynomal of degree k
β = np.linalg.solve(X.T@X+1e-20*np.eye(X.shape[1]), X.T@y)
plt.scatter(D,y, marker='o')
plt.plot(x,f_true(x))
plt.plot(x,poly.fit_transform(x.reshape(-1, 1))@β, color='hotpink')
plt.ylim(-1.3,1.3)
plt.title('k='+str(k))
p+=1
We can see that the found regression function is quite sensitive to the degree of the polynomial. Choosing \(k=1\) results in a too simple model, choosing \(k=4\) results in a regression function which is close to the true regression function and choosing \(k=16\) adapts very well to the data, but the difference to \(f^*\) is quite big, especially in those areas where we have only few observations (\(x\geq 0.6\)). But how can we determine the correct degree \(k\) in practice, when we can’t compare with the true regression function?
Evaluation with a Test Set: the Practice#
Since we don’t know the true regression function in practical applications, we resort to test the models ability to generalize. The idea is that a model which is close to the true regression function, should be able to predict \(y\) for unobserved \(\mathbf{x}\).
Idea: Hold out a test set, indicated by \(\mathcal{T}\subseteq\mathcal{D}\) from the \(n\) training data points and compute the error on the test data.
The Mean Squared Error (MSE) returns the average squared prediction error:
We apply a split to our synthetic dataset and evaluate then the MSE on the test data.
from sklearn.model_selection import train_test_split
D_train, D_test, y_train, y_test = train_test_split(D, y, test_size=0.3, random_state=18)
print(D_train.shape, D_test.shape)
(14,) (6,)
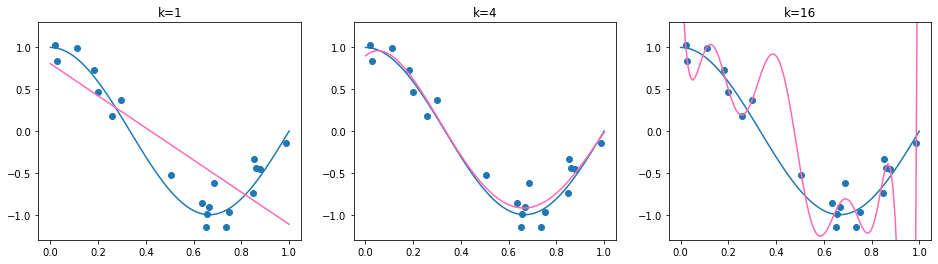
In the plot below, we show the training data in blue, the test data in orange and the learned regression functions in pink. The true regression function is again in blue. The title of each plot indicates the polynomial degree \(k\) and the MSE on the test set.
def mse(y_1,y_2):
return np.mean((y_1-y_2)**2)
plt.figure(figsize=(16, 4))
p = 1
for k in [1,4,16]:
plt.subplot(1, 3 , p)
poly = PolynomialFeatures(k)
X_train = poly.fit_transform(D_train.reshape(-1, 1)) #design matrix for polynomal of degree k
X_test = poly.fit_transform(D_test.reshape(-1, 1))
β = np.linalg.solve(X_train.T@X_train, X_train.T@y_train)
plt.scatter(D_train,y_train, marker='o')
plt.scatter(D_test,y_test, marker='*')
plt.plot(x,f_true(x))
plt.plot(x,poly.fit_transform(x.reshape(-1, 1))@β, color='hotpink')
plt.ylim(-1.3,1.3)
plt.title('k='+str(k)+', MSE:'+str(np.round(mse(X_test@β,y_test),2)))
p+=1
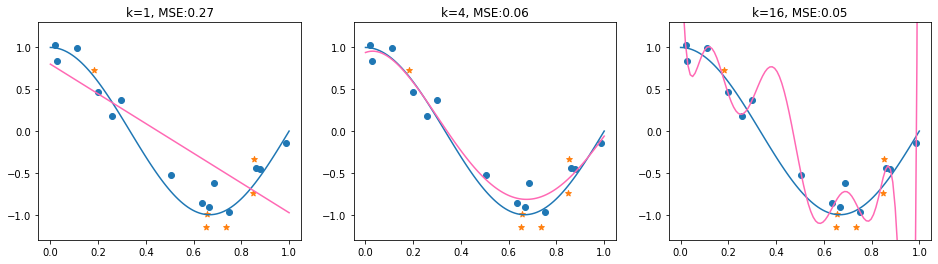
In the example above, the test MSE fails to identify the suitable model choice (\(k=4\)). The model with \(k=16\) obtains here the lowest MSE. Although this is not always the case (in fact, the MSE results are quite sensitive to the random_state of the train and test split), it may happen. This raises the question of how we can evaluate models in a more reliable and principled way. To address this, we view the construction of training and test datasets as a statistical process. This perspective allows us to reason about the expected performance of a model, rather than relying on a single split. In particular, it leads to a decomposition of the expected MSE into bias and variance, which helps us understand the fundamental sources of prediction error in practice.
Evaluation with a Test Set: the Theory#
In theory, the test-MSE results from the following process:
sample the (finite) training data \(\mathcal{D}_j\subset\mathbb{R}^{n_j\times d}\times \mathbb{R}\)
learn a model \(f_{\mathcal{D}_j}(\mathbf{x})=\bm{\phi}(\mathbf{x})^\top \bm{\beta}_j\) based on the training data,
sample a (finite) test set \(\mathcal{T}_j\subset\mathbb{R}^{m_j\times d}\times \mathbb{R}\)
compute \(MSE_j\)
If we repeat this sampling process \(t\) times, obtaining scores \(MSE_1,\ldots,MSE_t\), we could approximate the Expected squared Prediction Error (EPE). The expected squared prediction error returns the squared error of a model \(f(x)\) and target \(y\), where \(f\) is derived from training data \(\mathcal{D}\).
Definition 25 (EPE)
The Expected squared Prediction Error (EPE) is the expected error
\(\vvec{x}\) is the random variable of a feature vector in the test set.
\(y\) is the random variable of the target of \(\vvec{x}\).
\(\mathcal{D}\) is the random variable of the training data.
We can approximate the EPE with our sample MSEs:
The EPE is a theoretical construct. In practice, we have only one dataset. For the approximation of EPE, we would need multiple independently drawn datasets. Still, it makes sense to analyze the EPE to identify the characteristics that define theoretically guaranteed well performing models. We consider then how we can analyze said properties in the real world.
Regression Targets as Random Variables#
The target values \(y\) are not assumed to yield the true regression values per se. We can assume that the targets exhibit a natural amount of variance, reflecting random processes that influence the target. For example, target values such as the outside temperature fluctuate, even when it is measured every year at the same spot and the same time. Likewise, house prices are dependent on personal impressions on how much a house is worth, that can not reasonably be modeled in an observable feature space.
Property 1 (Target Value Distribution)
Given the true regression function \(f^*\) and observation \(\mathbf{x}_i\), we assume that the target value is generated as
We sample some training data with Gaussian noise, to observe the effect of \(\sigma\). The plot below indicates samples generated by the following procedure:
Sample \(x_{i}\in[0,1]\) for \(1\leq i \leq n\)
Sample \(\epsilon_i\) from \(\mathcal{N}(0,\sigma^2)\)
Set \(y_i=f^*(x_{i})+\epsilon_i\)
plt.figure(figsize=(16, 4))
p = 1
for sigma in [0.1,0.4]:
plt.subplot(1, 2 , p)
y = f_true(D) + np.random.normal(0,sigma,n)
x = np.linspace(0,1,100)
plt.plot(x,f_true(x))
plt.scatter(D,y) #plot the data points
plt.title('sigma='+str(sigma))
p+=1
The plot on the left is generated with a low variance (\(\sigma=0.1\)) and the plot on the right is generated with a larger variance (\(\sigma=0.4\)). Correspondingly, the target values with a low variance are closer to the true regression function than those with a bigger variance. It seems as if the true regression function is more easy to observe from the data in the left plot. Does that mean that it’s easier to approximate the true regression function if the variance is low? Surprisingly, that is not the case, as we will observe via the bias-variance trade-off.
The Bias-Variance Tradeoff#
The Bias-Variance Tradeoff describes the fit of a regression model to the true regression model by means of its bias and variance. It decomposes the EPE
Theorem 15 (Bias-Variance Tradeoff)
Given an observation \(\mathbf{x}_0\), whose target \(y\) is generated according to Property 1. Further, let \(\mathcal{D}\) denote the random variable that reflects the training set of regression model \(f_{\mathcal{D}}\). Then, the EPE for observation \(\mathbf{x}_0\) can be deconstructed into three parts:
Proof. We add and subtract \(f^*(x_0)\) in the squared error term of EPE, apply the binomial formula and the linearity of the expected value to get
The term on the left is the variance of the target value:
The first equality holds here because the term in the expectation doesn’t depend on \(\mathcal{D}\), and the last equality follows from Property 1. The second term in Eq. (15) is equal to zero, since the random variable \(y\), reflecting the raget of observation \(\mathbf{x}_0\) is independent from the training dataset \(\mathcal{D}\), and hence we can apply the expected value on each product term, giving
The product above is zero, since the expected value of \(y\) is \(f^*(x_0)\), and hence \(\mathbb{E}_{y}[(y-f^*(x_0))]=0\). The rightmost term in Equation (15) does only depend on the training data random variable now, and we expand it by adding and subtracting the expected value of the model output and applying again the binomial formula and the linearity of the expected value.
The term on the left is the squared bias. The outer expected value operator doesn’t do anything, because the argument is not dependent on a random variable anymore, and can be omitted. The rightmost term is the variance of the model. The middle term is again zero, because the left product term is a constant and can be multiplied outside of the expected value operator, yielding
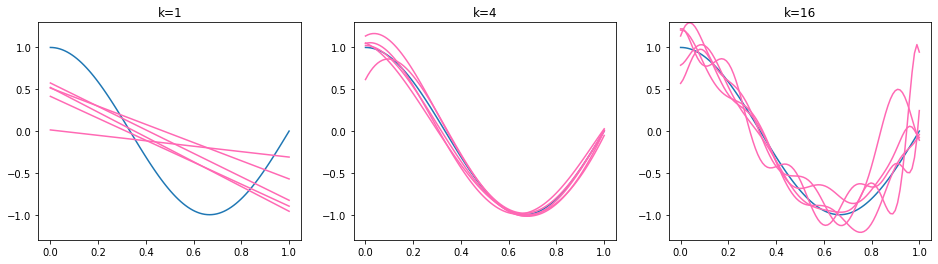
Hence, the expected squared prediction error is minimized for functions (models) having a low variance and low bias. We illustrate the effect by our running example. The true regression function is again \(f^*(x) = \cos(1.5\pi x)\) and the training set \(\mathcal{D}_j\) is sampled i.i.d. from the interval \([0,3]\) for each model \(f_{\mathcal{D}_j}\). We obtain five regression models for three polynomial function classes: affine functions (polynomials of degree \(k=1\)), polynomials of degree \(k=4\) and polynomials of degree \(k=16\). The obtained regression models \(f_\mathcal{D}\) are plotted below.
plt.figure(figsize=(16, 4))
p = 1
n=30
for k in [1,4,16]:
plt.subplot(1, 3 , p)
poly = PolynomialFeatures(k)
plt.plot(x,f_true(x))
for l in range(0,5):
D = np.random.uniform(-0.1,1.1,n) # sample n data points from a uniform distribution
y = f_true(D) + np.random.normal(0,0.15,n) # sample the target values
X = poly.fit_transform(D.reshape(-1, 1)) #design matrix for polynomal of degree k
β = np.linalg.solve(X.T@X, X.T@y)
plt.plot(x,poly.fit_transform(x.reshape(-1, 1))@β, color='hotpink')
plt.ylim(-1.3,1.3)
plt.title('k='+str(k))
p+=1
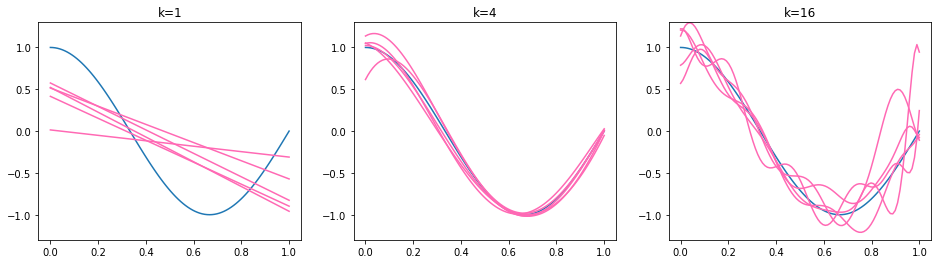
We observe that the functions on the left are too simple - affine functions can’t model the curvature of the true regression function. The affine functions show a low variance, they all go roughly from the top left to the bottom right. The functions in the middle (\(k=4\)) are all similar (low variance) and fit well to the true regression function (low bias). The functions on the right (\(k=16\)) follow the shape of the true regression function (low bias) but some of the lines differ a lot from the others (high variance). The bias of the higher degree models is not easy to see here, so we provide an additional visualization below. We recall that the bias represents the distance of the mean function value \(\mathbb{E}_\mathcal{D}[f_\mathcal{D}(\mathbf{x}_0)]\) and the true regression function. We illustrate the bias by plotting the mean of 500 regression models below in orange. Hence, the orange line approximates the mean function value \(\mathbb{E}_\mathcal{D}[f_\mathcal{D}(\mathbf{x}_0)]\).
fig = plt.figure(figsize=(16, 4))
p = 1
for k in [1,4,16]:
plt.subplot(1, 3 , p)
poly = PolynomialFeatures(k)
y_bias = np.zeros(x.shape[0])
nr_models=500
for l in range(0,nr_models):
D = np.random.uniform(-0.1,1.1,n) # sample n data points from a uniform distribution
y = f_true(D) + np.random.normal(0,0.15,n) # sample the target values
X = poly.fit_transform(D.reshape(-1, 1)) #design matrix for polynomal of degree k
β = np.linalg.solve(X.T@X, X.T@y) # learn the regression paarmeetr vector
y_bias += poly.fit_transform(x.reshape(-1, 1))@β # aggregate over the regression function values
plt.plot(x,f_true(x),label='$f^*$')
plt.plot(x,y_bias/nr_models, color='tab:orange', label="$approx. \mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]$")
plt.ylim(-1.3,1.3)
plt.title('k='+str(k))
line, label = fig.axes[0].get_legend_handles_labels()
fig.legend(line,label)
p+=1
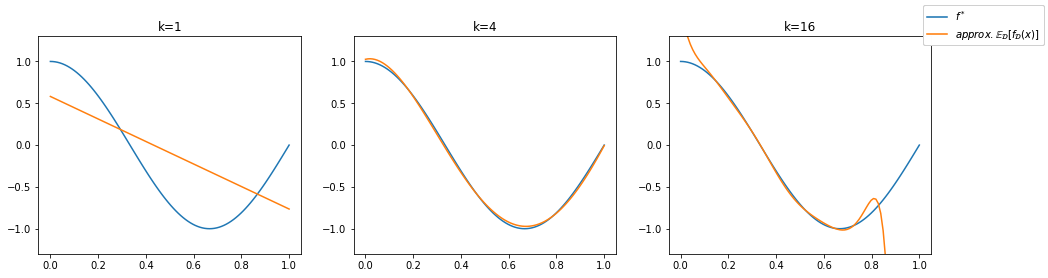
We can see that the polynomials of a degree \(k\geq 4\) approximate the true regression function well in average. This indicates a small bias. For \(k=16\) we see stark differences to the true regression function at the ends of the interval \([-0.1,1.1]\) in which we sample our data points, but this effect will diminish if the number of trained models goes to infinity. Especially at the interval ends, data might be sparse and the model is unguided, resulting in graphs that diverge quickly from the data distribution. Only the underfitting model using \(k=1\) is not able to reflect the true regression curve. We observe the approximated bias as the distance between the orange and the blue curve for each value on the horizontal axis.
In summary, we have discussed that the EPE is composed of three parts: the variance in the data (that we can’t influence), the squared bias (the squared distance of the expected model prediction to the true regression function) and the variance of the models. Those concepts are connected with the terms of under- and overfitting. An underfitting model has a high bias and a low variance, and an overfitting model has a high variance and a low bias. The models that we want are in the middle between under- and overfitting, achieving a low variance and bias.
Cross-Validation#
Now that we know what we expect in theory from a well-fitting model, we can think about applying this knowledge to practical model evaluations. A widely applied method that intends to mimick the evaluation process of generating multiple test-set MSEs to approximate the EPE is cross validation.
Algorithm 5 (\(k\)-fold CV)
Divide the data set into \(k\) disjunctive chunks, containing the data point indices
\[\{1,\ldots,n\}=\mathcal{I}=\mathcal{I}_1\cup\ldots \cup\mathcal{I}_k,\ \mathcal{I}_j\cap\mathcal{I}_l=\emptyset \text{ for } j\neq l\]For \(j\in\{1,\ldots,k\}\)
Obtain model \(f_{j}(\mathbf{x})=\bm{\phi}(\mathbf{x})^\top \bm{\beta}_j\) on the training data \(\mathcal{I}\setminus\mathcal{I}_j\)
Obtain the test-MSE \(MSE_j\) on test set \(\mathcal{I}_j\)
Return \(\frac{1}{k}\sum_{j=1}^k MSE_j\)
The k-fold cross validation computes the cross-validation MSE, given as
The cross-validation MSE seems to look like the average MSE from Equation (14) approximating the EPE. However, the training data of the cross-validation MSE is not sampled independently, because each of the folds depends on the others. In fact, the cross-validated MSE is a biased estimator of the EPE (any statistical estimator like the regression models follow the bias-variance tradeoff).
We’ll have a look now at a 3-fold cross validation for a Polynomial regression model with degree \(k=16\). We’ll use the sklearn \(k\)-fold split and print the indices of the train and test set.
n=20
D = np.random.uniform(0,1,n) # sample n data points from a uniform distribution
y = f_true(D) + np.random.normal(0,0.15,n)
from sklearn.model_selection import KFold
kf = KFold(n_splits=3, shuffle=True)
for train, test in kf.split(D):
print("train:"+str(train), " \ttest:"+str(test))
train:[ 0 1 2 4 5 7 9 10 12 13 14 15 16] test:[ 3 6 8 11 17 18 19]
train:[ 1 3 4 5 6 7 8 11 13 15 17 18 19] test:[ 0 2 9 10 12 14 16]
train:[ 0 2 3 6 8 9 10 11 12 14 16 17 18 19] test:[ 1 4 5 7 13 15]
Now, we compute the cross-validated MSE. The plots below show the split into training (blue) and test data (orange ) for each of the three folds. The fitted regression is plotted in pink. On the title you see the MSE for each of the folds, that are then averaged to compute the cross-validated MSE.
p=1
poly = PolynomialFeatures(16)
fig = plt.figure(figsize=(16, 4))
mse_array = []
for train, test in kf.split(D):
plt.subplot(1, 3 , p)
D_train, y_train = D[train], y[train]
D_test, y_test = D[test], y[test]
X_train = poly.fit_transform(D_train.reshape(-1, 1)) #design matrix for polynomal of degree k
X_test = poly.fit_transform(D_test.reshape(-1, 1))
β = np.linalg.solve(X_train.T@X_train, X_train.T@y_train)
plt.scatter(D_train,y_train, marker='o')
plt.scatter(D_test,y_test, marker='*')
plt.plot(x,f_true(x))
plt.plot(x,poly.fit_transform(x.reshape(-1, 1))@β, color='hotpink')
plt.ylim(-1.3,1.3)
plt.title('k=16, MSE:'+str(np.round(mse(X_test@β,y_test),2)))
mse_array.append(np.round(mse(X_test@β,y_test),2))
p+=1
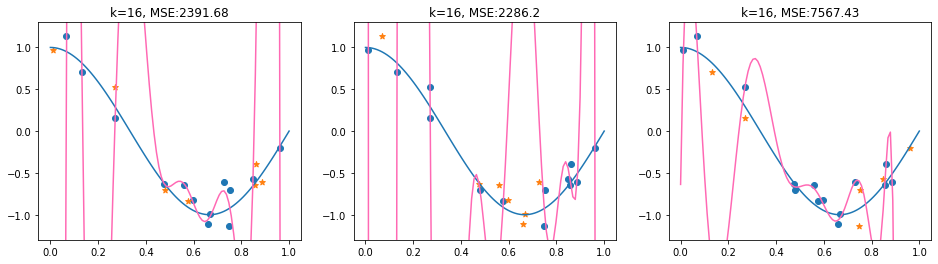
We observe that the thrid fold has a split into train and test data which does not really show that the polynomial is overfitting. However, in average, the 3-fold CV-MSE is large, in particular due to the very high MSE of the second fold.
np.mean(mse_array)
4081.77