Kernel SVM
Contents
Kernel SVM#
The classical Support Vector Machine (SVM) is a powerful linear classifier that provides a robust definition of a classifying hyperplane with the maximum margin hyperplane. However, in many real-world datasets, the classes are not linearly separable. This limits the applicability of the standard (linear) SVM.
The typical machine learning way to apply linear models to nonlinear data is to define a feature transformation that makes the nonlinear data appear linear in the transformed feature space. Often, the transformed feature space is higher dimensional than the original feature space. We have seen this for example in regression: applying polynomial basis functions creates a design matrix that is higher dimensional than the data matrix. Applying the linear regression on the design matrix solves the nonlinear regression problem in the original feature space.
For example, Fig. 6 illustrates how non-linearly separable classes can be transformed into a space where the classes are linearly separable.
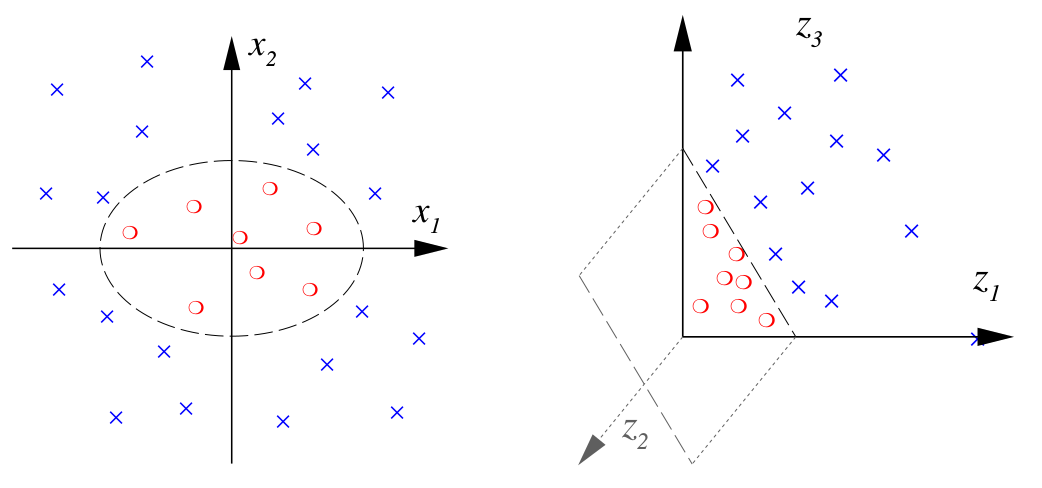
Fig. 6 Non-linear transformation \(\phi: \mathbb{R}^2 \rightarrow \mathbb{R}^3 \) mapping feature vectors \( {\bf x}\in\mathbb{R}^2\) to transformed feature vectors \( {\bf z}\in\mathbb{R}^3\) with the transformation \( {\bf z} = \phi({\bf x}) = ( x_1^2 , \sqrt{2} x_1 x_2 , x_2^2 ) \). (borrowed from [4]).#
The challenge of this approach is the high dimensionality that is often required to make classes linearly separable in the transformed feature space. The SVM dual objective enables here the application of the so-called kernel trick, that allows even for the efficient computation of infinite dimensional feature transformations.
Kernel trick#
The kernel trick is applicable when an objective can be formulated such that the only occurrences of data points are in inner products between data points \(\vvec{x}_i^\top\vvec{x}_j\). The kernel trick is to replace the inner products with a kernel function \(k(\vvec{x}_i,\vvec{x}_j)\). The kernel function represents an implicit computation of the inner product in a transformed feature space, that does not require the compuattion of the feature transformation itself: \(k(\vvec{x}_i,\vvec{x}_j)=\phi(\vvec{x}_i)^\top\phi(\vvec{x}_j)\). The kernel function has an interpretation as a similarity measure between two vectors. Choosing a kernel is hence equivalent to choosing what kind of similarity measure is considered suitable for the classification task. As a result, kernel methods are very flexible learners of nonlinear decision boundaries, that still allow for interpretability and control of their decision making process. Although they deal with very high-dimensional feature transformations that are not easy to understand, the inner product defined by the kernel has an interpretation as a similarity measure that still allows for understanding what the model is doing.
Definition 40 (Kernel)
A kernel function \(k:\mathbb{R}^d\times\mathbb{R}^d\rightarrow \mathbb{R}\) maps two \(d\)-dimensional vectors to a nonnegative value that has an interpretation as an inner product similarity measure in a transformed feature space. That is, a feature transformation \(\phi:\mathbb{R}^d\rightarrow \mathbb{R}^p\) exists such that
Popular kernels are the following:
Linear \( k({\bf x}_{i}, {\bf x}_{j}) = {\bf x}_{i}^\top {\bf x}_{j} \), which corresponds to working in the original feature space, i.e. \( \phi({\bf x}) = {\bf x} \);
Polynomial \( k({\bf x}_{i}, {\bf x}_{j}) = (1 + {\bf x}_{i}^\top {\bf x}_{j})^{p}\), which corresponds to \(\phi\) mapping to all polynomials – non-linear features – up to degree \(p\);
Gaussian \( k({\bf x}_{i}, {\bf x}_{j}) = \exp(-\gamma || {\bf x}_{i} - {\bf x}_{j} ||^{2}) \) (also called RBF-kernel), which corresponds in turn to an infinite feature space or functional space with infinite number of dimensions.
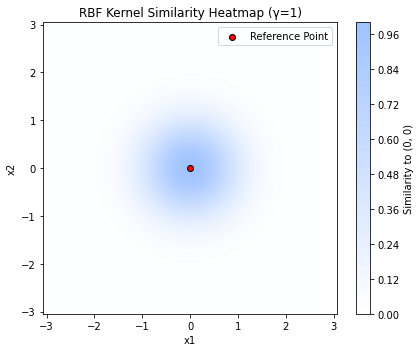
The plot below shows the similarity of 2D points to a reference point in the middle computed by the Gaussian kernel. We see that the Gaussian kernel considers points similar if they are close to each other – a very reasonable assumption, but to compute this similarity as an inner product requires an infinite-dimensional feature transformation.
Optimization#
The quadratic programming objective of the SVM (see Eq.(45)) is perfect for applying the kernel trick. The data points occur in this objective only over the inner product in the computation of \(DD^\top\), which computes the linear kernel matrix. We can replace \(DD^\top\) with a kernel matrix and obtain the kernel SVM objective
Definition 41 (Quadratic Program Kernel Soft-Margin SVM)
Given a kernel matrix \(K\in\mathbb{R}^{n\times n}\). The optimization objective of the kernel soft-margin SVM is given by the following quadratic program
where \(\mathbf{1}\in\{1\}^n\) is the constant one vector.
The quadratic program above is still convex and therefore we can compute the global optimum with a convex solver.
Inference#
When we apply the kernel trick, then we need to replace all operations on observations with operations on kernel similarities, since in general feature transformation \(\phi\) are computationally infeasible. To conduct the SVM inference only via kernel similarities, we recall from Eq.(43) that the optimal parameters of a soft- and hard-margin binary SVM model \(\hat{y}_{svm}(\vvec{x})=\sign(\vvec{w}^\top\vvec{x} +b)\) are given as
The definition of \(\vvec{w}^*\) over a weighted sum of observations helps us to formalize the inner product \(\mathbf{w}^\top \vvec{x}\) as a linear kernel \(k(\vvec{x}_i,\vvec{x}_j)=\vvec{x}_i^\top\vvec{x}_j\) operation
Likewise, we can compute the optimal bias term \(b^*\) via kernel similarities by substituting the optimal \(\vvec{w}^*\) in the definition of the optimal \(b^*\). Let \(i\) be such that \(\lambda_i>0\), then we have
Now, we can replace the linear kernel with any other kernel function and we can perform predictions for a kernel SVM without having to compute the feature transformation that defines the kernel.
Definition 42 (kernel SVM)
A kernel SVM classifier for a binary classification problem (\(y\in\{-1,1\}\)) reflects the distance to the decision boundary in a transformed feature space \(\vvec{w}^\top \phi(\vvec{x})+b=0\)
for some specified \(\lambda_i\geq 0\).
Decision Boundary#
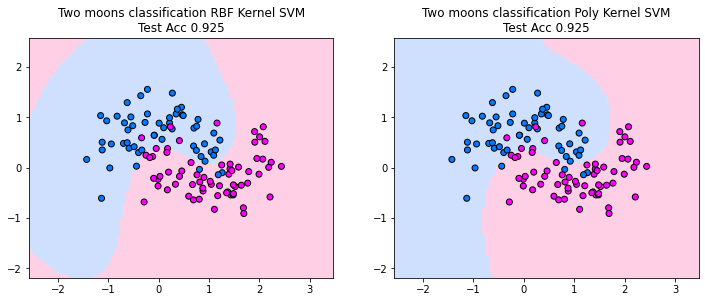
The plots below show the decision boundaries for the kernel SVM, using an RBF and a polynomial kernel. Both kernels are able to find decision boundaries that separate the training and test-data well. However, we also observe some undesired properties of the RBF kernel solution. The decision boundaries suggest that the classifier cuts out an area that is designated to predict the blue class, while the red class is the default class that is predicted otherwise. For the two moons, this does not make sense, since points that are on the top left are on the side of the blue moon and should be assigned to the blue moon. However, the classifier does not know of this intuition and hence we get here a different interpretation of the data by the classifier. When we can plot the data it is easy to see what is potentially problematic with a model, but in higher dimensions this becomes much more difficult.
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
from matplotlib.colors import ListedColormap, LinearSegmentedColormap
from sklearn.datasets import make_moons
from sklearn.svm import SVC
X,y = make_moons(noise=0.3, random_state=0, n_samples=200)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.4, random_state=42
)
# Define two SVM classifiers
svm_rbf = SVC(kernel='rbf', C=1.0, gamma=1.0)
svm_poly = SVC(kernel='poly', degree=3, C=1.0, coef0=1)
# Fit the models
y_pred_rbf = svm_rbf.fit(X_train, y_train)
y_pred_poly = svm_poly.fit(X_train, y_train)
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
cm = ListedColormap(["#a0c3ff", "#ffa1cf"])
cm_points = ListedColormap(["#007bff", "magenta"])
disp = DecisionBoundaryDisplay.from_estimator(
svm_rbf,
X,
response_method="predict",
plot_method="pcolormesh",
shading="auto",
alpha=0.5,
ax=axes[0],
cmap=cm,
)
scatter = axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, edgecolors="k",cmap = cm_points)
_ = axes[0].set_title(
f"Two moons classification RBF Kernel SVM\nTest Acc {np.mean(svm_rbf.predict(X_test) == y_test)}"
)
axes[0].axis('scaled')
disp = DecisionBoundaryDisplay.from_estimator(
svm_poly,
X,
response_method="predict",
plot_method="pcolormesh",
shading="auto",
alpha=0.5,
ax=axes[1],
cmap=cm,
)
scatter = axes[1].scatter(X_train[:, 0], X_train[:, 1], c=y_train, edgecolors="k",cmap = cm_points)
_ = axes[1].set_title(
f"Two moons classification Poly Kernel SVM\nTest Acc {np.mean(svm_poly.predict(X_test) == y_test)}"
)
axes[0].axis('scaled')
axes[1].axis('scaled')
plt.show()