Kernel k-means
Contents
Kernel k-means#
In many real-world applications, the assumption that data is linearly separable — as in standard k-means — is too restrictive. Similarly to the objective of PCA, the matrix factorization objective of k-means can be formulated only in dependence of the similarity between data points. This enables the application of the kernel trick.
Motivation: Beyond Linear Boundaries#
Standard k-means clustering identifies clusters by minimizing the within-cluster variance using Euclidean distances. This inherently restricts the method to discovering linearly separable, convex clusters, since the decision boundary between two centroids is always a hyperplane. But many real-world datasets exhibit complex, nonlinear structures.
For example, suppose we have data distributed in concentric rings or spiral shapes. In such cases, no linear boundary can adequately separate the clusters — standard k-means will fail. An example of the k-means clustering on the two circles dataset is below.
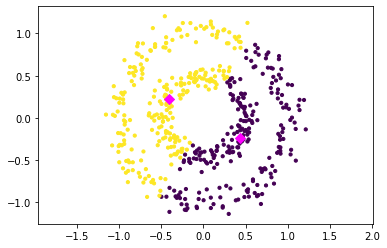
Formalizing the Kernel k-means Objective#
Fortunately, the k-means objective has many equivalent objectives, that are basically inherited from the equivalent objectives of the MF problem (compare for example with the PCA section). One of those objectives allows for the application of the kernel trick.
Theorem 39 (\(k\)-means trace objective)
Given a data matrix \(D\in\mathbb{R}^{n\times d}\), the following objectives are equivalent \(k\)-means objectives:
Proof. For \({\color{magenta}X=D^\top Y(Y^\top Y)^{-1}}\), we have
As a result, the objective function of \(k\)-means is equal to
for \(Z =Y (Y^\top Y)^{-1/2} \). Minimizing the term on the left is equivalent to minimizing the negative trace term on the right, which is equivalent to maximizing the trace term on the right.
The maximum trace objective is formulated only with respect to the inner product similarity between data points, given by the matrix \(DD^\top\). That is, the similarity between points with indices \(i\) and \(j\) are given by
Task (Kernel k-means)
Given a kernel matrix \(K\in\mathbb{R}^{n\times n}\), and the number of clusters \(r\).
Find clusters indicated by the matrix \(Y\in\mathbb{1}^{n\times r}\) maximizing the similarities of points within one cluster
Return the clustering \(Y\in\mathbb{1}^{n\times r}\)
Comparison of Inner Product Similarities#
Inner product similarities can be a bit tricky to understand at first. Why do they capture similarity? And what kind of structure do they reveal in the data?
To build some intuition, we visualize these similarities as a graph: every data point is connected to every other point with an edge, and the thickness of the edge reflects how similar the points are. Specifically, we only show edges with positive similarity to avoid clutter. The thicker the edge, the stronger the similarity.
Example 1: Two Blobs#
In the plot of the two blobs dataset below, we can see that the the upper-right cluster appears more tightly connected than the lower-left one. That is because inner product similarity is influenced not just by the direction between two points (like cosine similarity), but also by their norms (lengths). Specifically, we have:

So even if two pairs of points point in the same direction, the pair with longer vectors will have a larger inner product. This explains why clusters with longer vectors (like the top-right one) appear more strongly connected. As a result, the two blob data can be separated with the inner product similarity, since it’s beneficial not to break up the strongly connected cluster on the top right, and hence they get separated.
Example 2: Two Circles#
Next, we look at a two concentric circles dataset. Here, the structure is quite different.
For the two circles dataset (here it’s centered) plotted below, we observe that in particular points that the two circles are strongly connected. ALthough points on the outer circle are more strongly connected than points in the inner circle, the points that ar in the same direction are also well connected. This way, it’s more beneficial to separate the two circles as one would cut a donut.
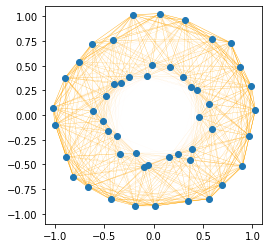
The points on the outer circle tend to be more similar to each other because their vectors are longer. However, points on different circles that point into the same direction (lying along the same ray from the origin) have high similarity, since the angle between them is small and one of the points has a high norm and the other has a lower norm. This causes strong connections between the circles, making the inner product similarity graph look more like a “donut” with strong radial connections. If we were to cluster this data based on inner product similarity, we would slice it like a donut into two halves with a (linear) cut of the knife.
Optimization#
To make use of the kernel trick in kernel k-means, we must find a way to optimize the clustering objective without explicitly computing the feature transformation \(\bm\phi\) that defines the kernel. This is crucial because many useful kernels (like the RBF kernel) map data into infinite-dimensional spaces, where direct computation is infeasible. The problem that we face is that we don’t know how to optimize the trace objective of the kernel Kernel k-means task directly. According to Theorem 39, the kernel k-means objective is equivalent to solving k-means in the transformed feature space:
Idea: Factorize the Kernel#
Instead of trying to work with the feature map, we compute a factorization of the kernel in another transformed feature space, that has maximally \(n\) dimensions. Since every kernel is a symmetric matrix, because the inner product is symmetric, we can apply the following fundamental result from linear algebra:
Theorem 40 (Eigendecomposition of symmetric matrices)
For every symmetric matrix \(K=K^\top\in\mathbb{R}^{n\times n}\) there exists an orthogonal matrix \(V\in\mathbb{R}^{n\times n}\) and a diagonal matrix \(\Lambda=\diag(\lambda_1,\ldots,\lambda_n)\) where \(\lambda_1\geq \ldots \geq \lambda_n\) such that
In particular, if all eigenvalues of \(K\) are nonnegative, we can write
We summarize this result in the following corollary.
Corollary 7 (Equivalent kernel \(k\)-means objectives)
Given a kernel matrix and its symmetric decomposition \(K=AA^\top\), the following objectives are equivalent:
Thanks to this result, we now have a way to formulate an algorithm for the kernel k-means task. We compute a symmetric decomposition \(AA^\top=K\) by means of the eigendecomposition \(A=V\Lambda^{1/2}\) and run \(k\)-means on \(A\).
Algorithm 16 (kernel k-means)
Input: kernel matrix \(K\), number of clusters \(r\)
\((V,\Lambda) \gets\)
Eigendecomposition\(K\)\(A\gets V\Lambda^{1/2}\) (\(AA^\top=K\))
\((X,Y)\gets\)
kMeans\((A,r)\)return \(Y\)
Application to the Two Circles Dataset#
Let’s try the kernel \(k\)-means idea on the two circles dataset. We use the RBF kernel to reflect similarities between points:

We compute the kernel matrix, apply \(k\)-means on the factor matrix \(V\Lambda^{1/2}\) and plot the resulting clustering by means of colored datapoints.
from sklearn.cluster import KMeans
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import rbf_kernel
D, labels = datasets.make_circles(n_samples=500, factor=.5, noise=0.08)
K= rbf_kernel(D, D,gamma=3)
lambdas, V = np.linalg.eig(K)
kmeans = KMeans(n_clusters=2,n_init=1)
A = np.abs(V)@np.diag(np.abs(lambdas)**(1/2))
kmeans.fit(A)
plt.scatter(D[:, 0], D[:, 1], c=kmeans.labels_, s=10)
plt.axis('equal')
plt.show()
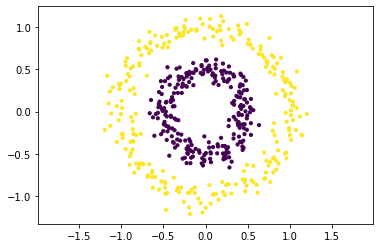
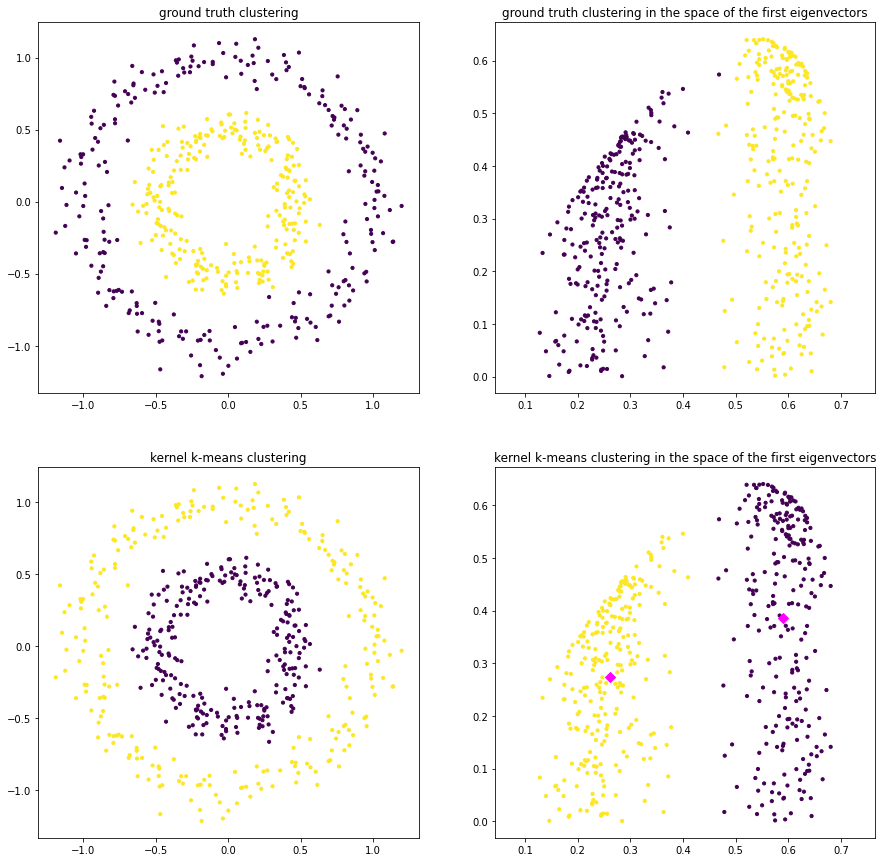
We see that kernel k-means is able to distinguish the two clusters perfectly. We try to get a feeling of the computed embedding defined by \(A=V\Lambda^{1/2}\) by plotting the transformed data points in the space spanned by the first two dimensions. That is, on the left you see the points in the original feature space. Points are colored according to the ground truth clustering on the top and according to kernel k-means clustering on the bottom. On the right we see the ground truth clustering in the feature space spanned by \(A_{\cdot \{1,2\}}\) at the top, and the k-means clustering at the bottom. The centroids are indicated by diamonds. We can see the clearly linearly separable structure of the two circles in the transformed feature space.
fig = plt.figure(figsize=(15, 15))
plt.subplot(2, 2, 1)
plt.scatter(D[:, 0], D[:, 1], s=10, c=labels)
plt.title("ground truth clustering")
plt.axis('equal')
plt.subplot(2, 2, 2)
plt.scatter(A[:, 0], A[:, 1], s=10, c=labels)
plt.title("ground truth clustering in the space of the first eigenvectors")
plt.axis('equal')
plt.subplot(2, 2, 3)
plt.scatter(D[:, 0], D[:, 1], s=10, c=kmeans.labels_)
plt.title("kernel k-means clustering")
plt.axis('equal')
plt.subplot(2, 2, 4)
plt.scatter(A[:, 0], A[:, 1], s=10, c=kmeans.labels_)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='magenta', s=50, marker = 'D')
plt.title("kernel k-means clustering in the space of the first eigenvectors")
plt.axis('equal')
plt.show()
Ok, so in theory we have a method to solve kernel \(k\)-means, but in practice this method is not often employed. Drawbacks of kernel \(k\)-means is a lack of robustness and the requirement of a full eigendecomposition. A related method based on a graph representation of the data facilitates nonconvex clustering based on a truncated eigendecomposition and takes into account results from graph theory to provide a more robust method.