k-Means
Contents
k-Means#
Clustering is a fundamental task in unsupervised learning, where the goal is to discover meaningful groupings in the data. Unlike supervised learning, there is no target to learn — the algorithm must infer structure based solely on the features of the data.
One of the most widely used clustering algorithms is k-means, which aims to partition a dataset into \(r\) clusters such that points within each cluster are close to each other in feature space. Traditionally, the number of clusters is denoted by \(k\), which gives the algorithm its name. In this course we use \(r\) to avoid conflicts with notation introduced elsewhere. Despite k-means being a very simple method, it often reveals interpretable structure and serves as a useful baseline in exploratory data analysis.
Motivation#

Fig. 12 A deck of cards can be clustered into various forms of valid clusterings.#
To understand the nature of clustering, consider a simple dataset: a standard deck of 52 playing cards. Each card can be described using features like:
Suit (Hearts, Diamonds, Clubs, Spades)
Rank (2 through 10, Jack, Queen, King, Ace)
Color (Red or Black)
Now imagine you’re asked to cluster this dataset into groups. What are some reasonable ways to group the cards?
You could group them by suit — forming four clusters (Hearts, Diamonds, Clubs, Spades).
You could group them by rank — so that all Aces are together, all 2s are together, and so on.
You could group by color — two clusters: red cards and black cards.
You could even define groups based on custom similarity, such as grouping all face cards together or separating prime-numbered cards.
Each of these groupings is valid depending on what we consider similar or meaningful. This illustrates a core aspect in clustering: it has no universally correct answer. The grouping that we want depends on our assumptions about the ground truth clustering.
Because k-means measures similarity using Euclidean distances, it works best when clusters are roughly compact and blob-shaped. Hence, motivating examples for k-means often look like the blobs below:
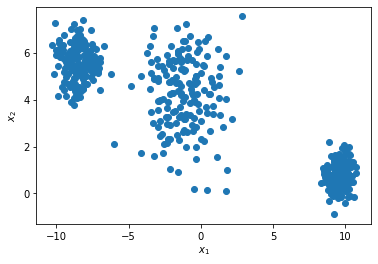
We can visually see that there are three clusters – three point clouds that are visibly separated from each other. However, if our data has more than two dimensions, then it becomes difficult up to impossible to detect the clusters visually. In these cases, k-means is supposed to give us the clusters, assuming the clusters are as nicely shaped as in this two-dimensional blobs example.
Formal Problem Definition#
The k-means algorithm makes specific assumptions about the clustering structure:
Data points are vectors in Euclidean space (i.e., numerical features) and their distance is measured by Euclidean distance,
Every data point belongs to exactly one cluster,
Points within one cluster should be close together in Euclidean distance.
We denote our clustering as a series of indices-sets \(\mathcal{C}_1,\ldots,\mathcal{C}_r\), where \(\mathcal{C}_s\subseteq \{1,\ldots,n\}\) indicates the indices of our \(n\) data points that belong to cluster \(s\). The second assumption is then mathematically described by \(\mathcal{C}_1,\ldots,\mathcal{C}_r\) forming a partition of \(\{1,\ldots,n\}\), that is
Point 3 states that points within a cluster are similar. We can express this assumption mathematically by stating that points within a cluster have a small (squared) Euclidean distance in average:
Task (k-means)
Given a data matrix \(D\in\mathbb{R}^{n\times d}\) and the number of clusters \(r\).
Find clusters \(\{\mathcal{C}_1,\ldots,\mathcal{C}_r\}\in\mathcal{P}_n\) which create a partition of \(\{1,\ldots,n\}\), minimizing the distance between points within clusters (within cluster scatter):
Return the clusters \(\mathcal{C}_1,\ldots,\mathcal{C}_r\)
Optimization#
The objective in the k-means task is not easy to optimize. In particular the discrete nature of assigning points to clusters is problematic, since we can’t apply our numerical optimization schemes to a discrete optimization task. As so often with nasty objectives, it is also here possible to transform this objective into a form that gives a clearer idea on how to optimize it.
A natural representative of a cluster is its centroid, i.e. the average position of all points in the cluster. We will now show that minimizing within-cluster scatter is equivalent to minimizing distances of points within one cluster to their centroid. Intuitively, this makes sense because if all points in a cluster are close to one another, then they should also be close to their average position. The theorem below formalizes this intuition.
Theorem 33
The \(k\)- means objective in Eq. (63) is equivalent to
Proof. The objective function in Eq. (63) returning the average distance of points within one cluster can be transformed as follows:
This transformation introduces the centroid to the objective, it is given by the term on the right:
\(X_{\cdot s}\) is the centroid (the arithmetic mean position) of all points assigned to cluster \(\mathcal{C}_s\). We rearrange the terms now, such that we can again apply the binomial formula for norms, where the norm is used to measure the distance of a point in a cluster to the corresponding centroid:
The step from the first to the second equation follows by adding and subtracting the term \(\sum_{i\in\mathcal{C}_s}\lVert X_{\cdot s}\rVert^2= \sum_{i\in\mathcal{C}_s} D_{i\cdot}X_{\cdot s}\).
\(X_{\cdot s}\) is the centroid (the arithmetic mean position) of all points assigned to cluster \(\mathcal{C}_s\).
Minimizing the distance of points to their centroids suggests an iterative two-step procedure, where we optimize subject to the centroids in one step and the clustering in the next step. As an example, let’s consider the clustering of the three blobs data starting with some randomly sampled centroids (in magenta).
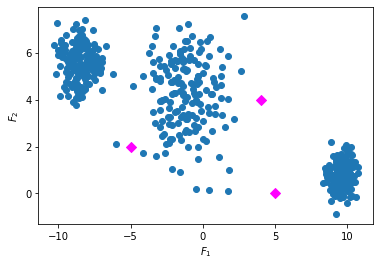
We assign every point to the cluster with the closest centroid.
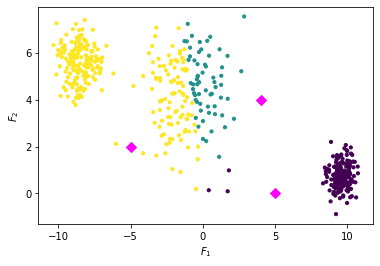
Now the centroids are not actually centroids of all points in one cluster. Hence, we update the centroids.
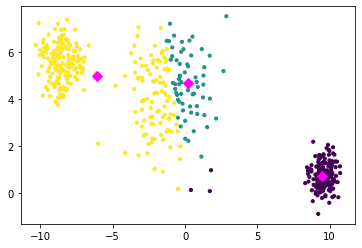
Now we can again decrease the objective function by assigning the points to their closest centroid. We repeat the steps of assigning the points to their closest centroid and recomputing the centroids until the function value doesn’t decrease anymore. This is known as the k-means algorithm. We show in the following video the steps until convergence for our example.
This two step procedure has been proposed in 1957 by Stuart Lloyd. Interestingly, his work wasn’t widely known until it was published in a technical report in 1982, and by then the algorithm had already been rediscovered multiple times under different names in various fields. In the context of clustering, it became known as the standard way to solve the k-means problem. The algorithm below details the procedure.
Algorithm 15 (k-means (a.k.a. Lloyds algorithm))
Input: \(D, r\)
\(X\gets\)
initCentroids\((D, r)\) (centroid initialization)while not converged
for \(s\in\{1,\ldots,r\}\) (cluster assignment)
\(\displaystyle\mathcal{C}_{s} \gets \left\{i\middle\vert s =\argmin_{1\leq t\leq r}\left\{\|X_{\cdot t}-D_{i\cdot}^\top\|^2\right\},1\leq i\leq n\right\}\)
for \(s\in\{1,\ldots,r\}\) (centroid computation)
\(\displaystyle X_{\cdot s}\gets \frac{1}{|\mathcal{C}_s|}\sum_{i\in\mathcal{C}_s}D_{i\cdot}^\top\)
return \(\{\mathcal{C}_1,\ldots,\mathcal{C}_r\}\)