Backpropagation
Contents
Backpropagation#
Neural networks have a lot of parameters. Every layer introduces \(d_j\cdot d_{j+1}\) parameters for the weight matrix and \(d_{j+1}\) parameters for the bias term. The composition of affine functions and nonlinear activations make it infeasible to compute the optimum analytically, also not if we fix all other weights. Hence, applying FONC or coordinate descent is out, and we resort to gradient descent, or one of its variants. To do so, we need to discuss how to get the gradient of neural networks.
Computing the Gradient of a Neural Network#
We consider the optimization of our loss function, the average cross entropy
where
and the hidden layers are recursively defined
The layer-wise definition of a neural network is helpful to compute the gradient of the loss with the chain rule. This motivates the so-called backpropagation algorithm that is in essence an efficient implementation of the chain rule. Let’s have a look how we would apply the chain rule to the loss function above. First, we notice that the gradient subject to \(\theta\) gathers all partial derivatives subject to all parameters, that is
Let’s have a look how we can determine the partial derivative of the loss subject to weight matrix entry \(W^{(\ell)}_{kj}\).
We have a look at the partial derivative of the cross entropy and apply the chain rule to go back from the cross entropy loss, that is applied to the output layer, to the layer where we find the weight \(W^{(\ell)}_{kj}\):
We can see how the gradient multiplies the Jacobians of each activation and the affine function of each layer. Hence, if we know the derivatives of the activations, then we can compute the Jacobian. We also observe how we go from the output layer of the network to the front of the network where the weight \(W^{(\ell)}_{kj}\) is. This is why it’s called backpropagation, we propagate backwards the partial derivatives (Jacobians) of the layers and multiply them.
In order to compute the partial derivatives with the chain rule, we need to know now how to compute the derivatives subject to the layer components, such that we can multiply everything well together.
Derivative of the Cross Entropy Loss#
The cross-entropy loss has a compact representation of the derivative subject to the last hidden layer output.
Lemma 7
The partial derivatives of the cross-entropy function, applied to a function \(f(\vvec{x})=\softmax(\vvec{h}(\vvec{x}))\) that returns the softmax of an affine function
Derivatives of Affine Functions#
We already know the Jacobian of the affine functions subject to the hidden layer outputs (see the Optimization exercises):
Derivatives of Activations#
Lemma 8
The (sub-)derivative of the \(ReLU(x)=\max\{x,0\}\) function is
Note
Although the derivative of ReLU does not exist strictly speaking, practical implementations gloss over this fact and set
Correspondingly, we obtain as the Jacobian of the element-wise applied activation function a diagonal matrix (see Theorem 12)
Corollary 5
The Jacobian of the ReLU activation subject to a vector \(\vvec{x}\in\mathbb{R}^d\) is given as
Training a Neural Network in Pytorch#
We use the automatic differentiation in Pytorch to train our MLP from the previous section on the two moons data. We choose a dimensionality of \(d_2=2\) of the last hidden layer, such that we can inspect the learned representation learned for this example. The function train_model performs 1000 gradient descent steps with momentum. The gradient descent steps are implemented by optimizer.step(). Computing the loss and running loss.backward() computes the gradient that is then used by the optimizer.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from matplotlib.colors import ListedColormap, LinearSegmentedColormap
cm_0 = LinearSegmentedColormap.from_list("mycmap", ["#ffffff","#a0c3ff"])
# Generate and prepare data
X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
# Two hidden layers: input -> hidden -> 2D latent -> output
class TwoHiddenLayerNet(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(2, 264)
self.latent = nn.Linear(264, 2)
self.output = nn.Linear(2, 2)
def forward(self, x):
x = torch.relu(self.hidden(x))
z = torch.relu(self.latent(x))
return self.output(z)
def get_latent(self, x):
x = torch.relu(self.hidden(x))
return self.latent(x)
# Training function
def train_model(model, X, y, t_max=1000, lr=0.01, momentum=0.99):
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
loss_fn = nn.CrossEntropyLoss()
for t in range(t_max):
model.train()
optimizer.zero_grad()
output = model(X)
loss = loss_fn(output, y)
if t%100==0: #print
_ , predicted = output.max(1)
correct = predicted.eq(y).sum().item()
print('Iter %i | Loss: %.3f | Train Acc: %.3f%%'% (t,loss, 100.*correct/y.shape[0]))
loss.backward()
optimizer.step()
return model
# Train and plot
model = train_model(TwoHiddenLayerNet(), X_train_tensor, y_train_tensor)
Iter 0 | Loss: 0.806 | Train Acc: 50.000%
Iter 100 | Loss: 0.319 | Train Acc: 86.000%
Iter 200 | Loss: 0.240 | Train Acc: 88.375%
Iter 300 | Loss: 0.151 | Train Acc: 95.250%
Iter 400 | Loss: 0.088 | Train Acc: 96.875%
Iter 500 | Loss: 0.070 | Train Acc: 97.750%
Iter 600 | Loss: 0.065 | Train Acc: 97.375%
Iter 700 | Loss: 0.062 | Train Acc: 97.625%
Iter 800 | Loss: 0.060 | Train Acc: 97.625%
Iter 900 | Loss: 0.059 | Train Acc: 97.750%
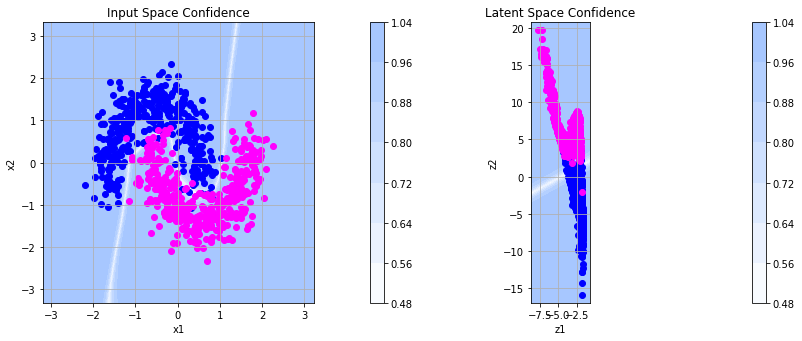
We inspect the representations learned below. On the left you see the classification confidences returned by softmax in the original space. Most runs of the optimization procedure yield a suitable classification boundary that reflects the curves between the two moons well. On the right you see the representation in the transformed feature space where the points are linearly separable.
import torch
import numpy as np
import matplotlib.pyplot as plt
import torch.nn.functional as F
def plot_latent_and_input(model, X, y, cm_0, title=""):
model.eval()
with torch.no_grad():
Z = model.get_latent(X).numpy()
X_np = X.numpy()
y_np = y.numpy()
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# ----------------------
# Plot in latent space
# ----------------------
ax = axes[1]
d, c = 2, 2
x_ = np.arange(Z[:, 0].min()-1, Z[:, 0].max()+1, 0.02)
y_ = np.arange(Z[:, 1].min()-1, Z[:, 1].max()+1, 0.02)
xx, yy = np.meshgrid(x_, y_)
XY = np.c_[xx.ravel(), yy.ravel()]
with torch.no_grad():
logits_latent = model.output(torch.tensor(XY, dtype=torch.float32))
conf_latent = F.softmax(logits_latent, dim=1).numpy().T
conf_latent = conf_latent.reshape(c, len(y_), len(x_))
ax.contourf(x_, y_, conf_latent.max(axis=0), cmap=cm_0)
fig.colorbar(ax.contourf(x_, y_, conf_latent.max(axis=0), cmap=cm_0), ax=ax)
ax.set_title("Latent Space Confidence")
ax.scatter(Z[y_np==0, 0], Z[y_np==0, 1], c='blue', label='Class 0')
ax.scatter(Z[y_np==1, 0], Z[y_np==1, 1], c='magenta', label='Class 1')
ax.set_xlabel("z1")
ax.set_ylabel("z2")
ax.axis('scaled')
ax.grid(True)
# ----------------------
# Plot in input space
# ----------------------
ax = axes[0]
x_ = np.arange(X_np[:, 0].min()-1, X_np[:, 0].max()+1, 0.02)
y_ = np.arange(X_np[:, 1].min()-1, X_np[:, 1].max()+1, 0.02)
xx, yy = np.meshgrid(x_, y_)
XY_input = np.c_[xx.ravel(), yy.ravel()]
with torch.no_grad():
logits_input = model(torch.tensor(XY_input, dtype=torch.float32))
conf_input = F.softmax(logits_input, dim=1).numpy().T
conf_input = conf_input.reshape(c, len(y_), len(x_))
ax.contourf(x_, y_, conf_input.max(axis=0), cmap=cm_0)
fig.colorbar(ax.contourf(x_, y_, conf_input.max(axis=0), cmap=cm_0), ax=ax)
ax.set_title("Input Space Confidence")
ax.scatter(X_np[y_np==0, 0], X_np[y_np==0, 1], c='blue', label='Class 0')
ax.scatter(X_np[y_np==1, 0], X_np[y_np==1, 1], c='magenta', label='Class 1')
ax.set_xlabel("x1")
ax.set_ylabel("x2")
ax.axis('scaled')
ax.grid(True)
plt.suptitle(title)
plt.tight_layout()
plt.show()
plot_latent_and_input(model, X_train_tensor, y_train_tensor, cm_0)