Numerical Optimization
Contents
Numerical Optimization#
We have seen some strategies to find a solution to optimization objectives by means of solving a system of equations. These strategies work usually fine for simple objectives, but if I have a lot of valleys and hills in my optimization objective, then solving this system of equations analytically will not always be possible. What can we do then?
If the minimizers can not be computed directly/analytically, then numerical optimization can come to the rescue. The idea is that I start somewhere in my hilly landscape and then try to walk to a valley with a specified strategy. For those types of methods it’s good to know how good the strategy is. Important is for example to ask whether I will ever arrive at my minimum if I just walk long enough, or if I have to wonder endlessly around in a bad case. And what happens if I just walk a few steps, would I then have improved upon my starting position or might I not have descended at all? We state here two very popular numerical optimization methods: coordinate descent and gradient descent. Both are presented for the optimization of an unconstrained objective, but they do have extensions to incorporate constraints as well. This is beyond of the scope of this course, though.
The general scheme of numerical optimization methods is typically
Algorithm 1 (Numerical Optimization)
Input: the function \(f\) to minimize, the maximum number of steps \(t_{max}\)
\(\vvec{x}_0\gets\)
Initialize(\(\vvec{x}_0\))for \(t\in\{1,\ldots,t_{max}-1\}\)
\(\vvec{x}_{t+1}\gets \)
Update(\(\vvec{x}_t,f\))
return \(\vvec{x}_{t_{max}}\)
Coordinate descent#
The coordinate descent method is promising if we can not determine the minimum to the function analytically, but the minimum in a coordinate direction. The update is performed by cycling over all coordinates and walking to the minimum subject to that coordinate in each step.
Algorithm 2 (Coordinate Descent)
Input: the function \(f\) to minimize
\(\vvec{x}_0\gets\)
Initialize(\(\vvec{x}_0\))for \(t\in\{1,\ldots,t_{max}-1\}\)
for \(i\in\{1,\ldots d\}\) do
\(\displaystyle {x_i}^{(t+1)}\leftarrow \argmin_{x_i} f({x_1}^{(t+1)},\ldots ,{x_{i-1}}^{(t+1)}, x_i,{x_{i+1}}^{(t)},\ldots ,{x_d}^{(t)})\)
return \(\vvec{x}_{t_{max}}\)
The figure below shows the level set of a function, where every ring indicates the points in the domain of the function that have a specified function value \(\{\vvec{x}\mid f(\vvec{x})=c\}\). The plotted function has a minimum at the center of the ellipses. We start at \(\vvec{x}_0\) and then move to the minimum in direction of the vertical coordinate. That is, we move to the smallest ellipse (smallest diameter) we can touch in direction of the vertical coordinate. Then we move to the minimum in direction of the horizontal coordinate and we are already at our minimum where the method stops.

Coordinate descent minimizes the function value in every step:
Example: Rosenbrock function#
Let’s try to apply coordinate descent to find the minimum of the Rosenbrock function. From Example 7 we know the partial derivatives of the function
We compute the minima of the function in direction of the coordinates as would normally compute the minima of a polynomial: set the derivative to zero. Unfortunately, this doesn’t work well for the partial derivative subject to \(x_1\). Using symbolic solvers like sympy give three roots of the partial derivative, of which two are complex numbers. The one real-valued root is only defined for \(x_1\) no larger than a constant that is close to zero. Hence, this example doesn’t work well for coordinate descent, we exemplify the trajectory nevertheless until the roots are not defined anymore. The minimizer of the function subject to coordinate \(x_2\) is easily computed by setting the partial derivative to zero:
Hence, we have update rules:
The figure below shows the result of these update rules when starting at \((-1.5,-1)\). We see that in the beginning we make big steps towards the minimizer (1,1), but then those steps get smaller and smaller once we are in the valley.
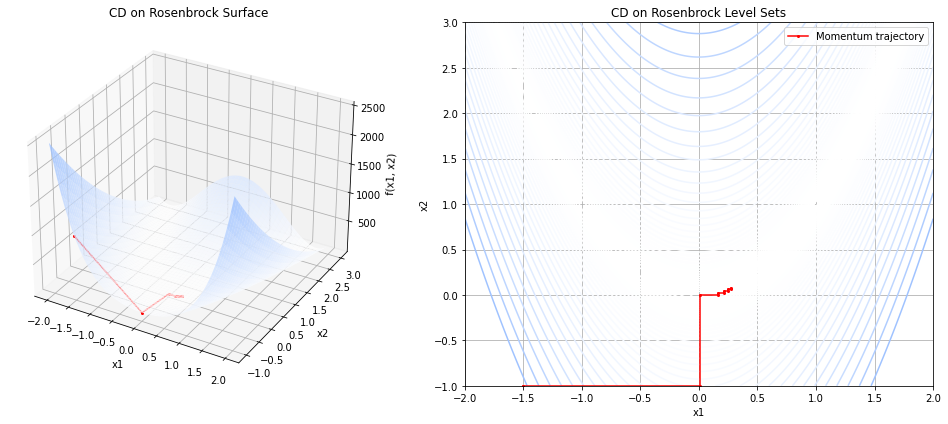
Gradient Descent#
If we can’t solve the system of equations given by FONC, also not coordinate-wise, but the function is differentiable, then we can apply gradient descent. Gradient descent is a strategy according to which you take a step in the direction which goes down the most steeply from where you stand.
Definition 24
The directional derivative of a real-valued function \(f:\mathbb{R}^d\rightarrow \mathbb{R}\) along the direction given by the vector \(\vvec{v}\in\mathbb{R}\) is the function
The directional derivative generalizes the concept of a derivative from one dimension to multiple ones. The plot below shows a 3D function and a direction vector \(\vvec{v}\) (red) at point \(\vvec{x}_0=(1,1)\). The directional derivative is then the tangent at point \(\vvec{x}_0\) in the direction of \(\vvec{v}\) (plotted on the left).
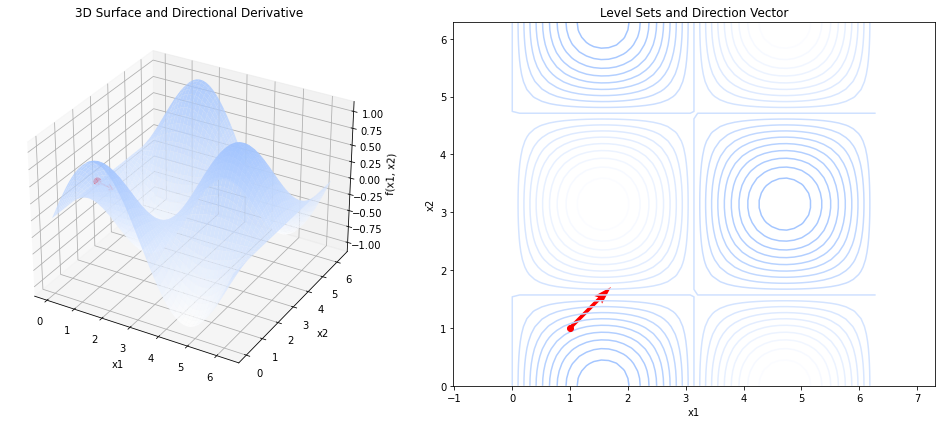
We can also visualize the directional derivative as the slope of the tangent at point \(\vvec{x}_0\) when we project the graph of the 3D function on the direction given by \(\vvec{v}\). The red vector on the right plot indicates the direction \(\vvec{v}\) and the slope of the orange tangent on the left is the directional derivative in the direction of \(\vvec{v}\).