Decision Trees
Contents
Decision Trees#
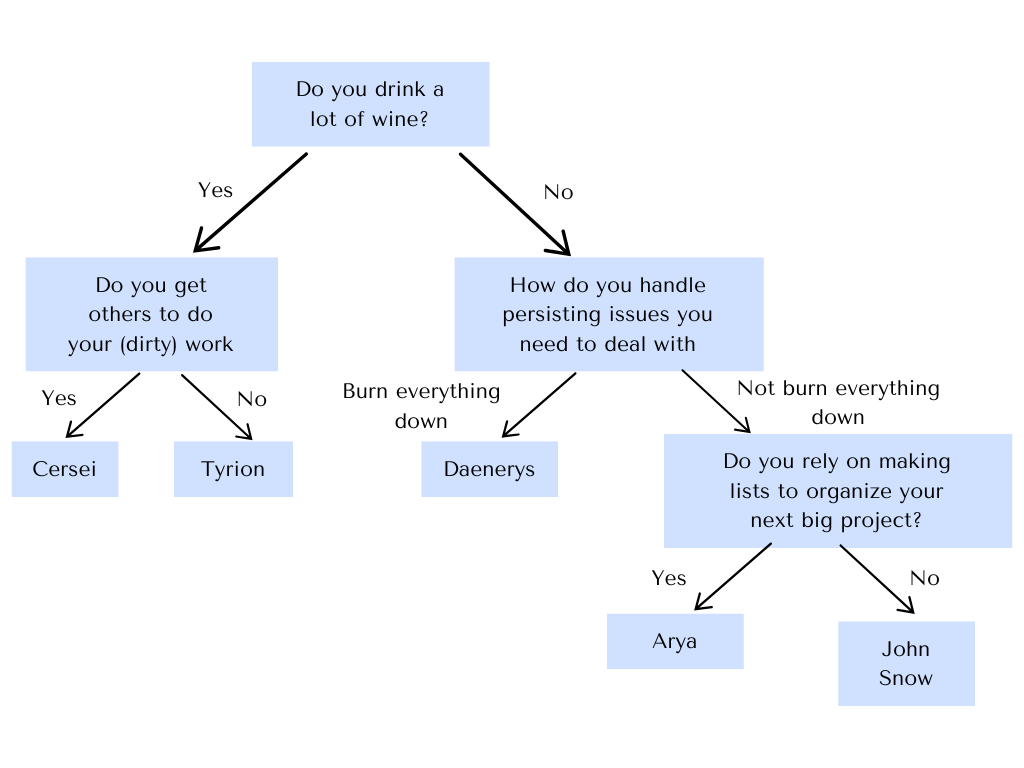
Fig. 3 A decision tree Game of Thrones personality test.#
Decision trees are a fundamental method in machine learning due to their inherently interpretable structure. They model decisions in a tree-like structure, where each internal node splits the outcomes based on a feature value, until we arrive at a leaf node that assigns a class prediction. This structure is so intuitive, that no further information is needed to perform the inference step. As an example, have a look at the Game of Thrones personality test decision tree above. You probably already got your character prediction without having to know what a decision tree is. This is particularly useful when you work in application domains where your project partners have no deepened mathematical training, for example in the medical domain. You can show a decision tree to experts of their field and they will be able to assess whether the predictions are sensible. Of course, this advantage gets lost if the decision tree is very big.
One of the most widely used algorithms for constructing decision trees is the CART (Classification and Regression Trees) algorithm, which builds binary decision trees using impurity measures such as Gini impurity (for classification).
Inference#
Definition 34 (Decision Tree)
A Decision Tree is a directed binary tree that represents a classifying function \(f_{dt}:\mathbb{R}^d\rightarrow [0,1]^c\). The classifying function is defined recursively:
the decision function \(q:\mathbb{R}^d\rightarrow \{0,1\}\) performs a test on a feature of the input \(\vvec{x}\) that is either true (returning 1) or false (returning 0).
the function \(f_b:\mathbb{R}^d\rightarrow [0,1]^c\) returns either directly a probability vector over all classes, or it is recursively defined as
\[f_b(\vvec{x}) = q_b(\vvec{x}){f_b}_0(\vvec{x}) + (1-q_b(\vvec{x})){f_b}_1(\vvec{x}).\]
In the tree, these functions are represented by
Decision nodes: each decision function \(q_b\) is represented by an internal node, performing a split based on feature values.
Prediction nodes: each function \(f_b(\vvec{x})=\vvec{p}\) that directly returns a probability vector over all classes, (that is hence not defined over further recursions) is represented by a leaf node.
Although decision trees are often represented as if they only store the predicted label at a leaf, in practice, the class probabilities are stored. Class probabilities are useful as a confidence measure of the prediction \( \hat{y} = \argmax_y\ f_{dt}(\vvec{x}) \).
Training#
We provide the pseudocode for the recursive creation of the Classification and Regression Tree (CART) algorithm [2] in Algorithm 8. The input of CART is here specified to be the dataset \(\mathcal{D}\) only, but in principle CART has various hyperparameters that are here summarized by the hard-coded stopping criterion. We discuss possible stopping criteria in a subsection below. If the stopping criterium is satisfied, then the CART algorithm returns a probability vector that reflects the empirical class-distribution in the dataset \(\mathcal{D}\)
Otherwise, a split is found (to be discussed below), returning the decision function \(q\) and the split datasets \(\mathcal{L}_0\cup \mathcal{L}_1 = \mathcal{D}\). CART proceeds then with the recursion.
Algorithm 8 (Classification and Regression Tree (CART))
Input The dataset \({\cal D} \)
Function \(\mathtt{CART}({\cal D})\)
if stopping criterion is satisfied:
return class probability vector \(\vvec{p}\in[0,1]^c\) such that \(p_y = p_\mathcal{D}(y)\) for \(1\leq y\leq c\)
else
\(q,\ \mathcal{L}_0\), \(\mathcal{L}_1\leftarrow\mathtt{split}(\mathcal{D})\)
return \(q\circ \mathtt{CART}(\mathcal{L}_0) + (1-q) \circ \mathtt{CART}(\mathcal{L}_1) \)
Finding Splits#
Decision tree splits are determined using a greedy approach, meaning each split is chosen based on the immediate best improvement for the classification task. Greedy methods are usually easy to implement and to understand and provide good enough solutions, but the model decisions are often short sighted, such that the resulting tree might be bigger than it would be needed. The improvement is measured by the information gain (\(IG\)), which is high when the resulting child nodes have a purer class distribution than the parent node. A more detailed discussion of this concept follows below.
Algorithm 9 (Split)
Input A dataset \({\cal D}\)
Function \(\mathtt{split}({\cal D})\)
\(\mathtt{max\_ig}\), \(q^*\), \(\mathcal{L}_0^*\), \(\mathcal{L}_1^*\) \(\leftarrow 0,\ \emptyset,\ \emptyset,\ \emptyset\)
for \(k\in\{1,\ldots, d\}\)
for \(t\in\mathtt{thresholds}(\mathtt{x}_k, \mathcal{D})\)
\(q(\vvec{x})=\begin{cases}1& \text{ if } x_k= t\ (\mathtt{x}_k \text{ is discrete) or } x_k\geq t\ (\mathtt{x}_k \text{ is continuous})\\0& \text{ otherwise}\end{cases}\)
\(\mathcal{L}_0\leftarrow \{(\vvec{x},y)\in\mathcal{D}\mid q(\vvec{x})=1\}\)
\(\mathcal{L}_1\leftarrow \mathcal{D}\setminus \mathcal{L}_0\)
if \(IG(\mathcal{D},\mathcal{L}_0,\mathcal{L}_1)>\mathtt{max\_ig}\)
\(\mathtt{max\_ig}\leftarrow IG(\mathcal{L}_0,\mathcal{L}_1,\mathcal{D})\)
\(\mathcal{L}_0^*\), \(\mathcal{L}_1^*\leftarrow \mathcal{L}_0,\ \mathcal{L}_1\)
\(q^*\gets q\)
return \(q^*\), \(\mathcal{L}_0^*\), \(\mathcal{L}_1^*\)
The function \(\mathtt{thresholds}(\mathtt{x}_k,\mathcal{D})\) can be defined in various ways. A straightforward choice is for discrete features \(\mathtt{x}_k\) to return the set of unique values in the dataset:
Information Gain#
The information gain measures how beneficial a split is to the classification task. A split is defined over a data sub-set \(\mathcal{L}\) that is split into disjoint data sub-sets \(\mathcal{L}=\mathcal{L}_0\cup\mathcal{L}_1\). The more pure the split datasets \(\mathcal{L}_0\) and \(\mathcal{L}_1\) are in comparison to their parent dataset \(\mathcal{L}\), the higher the information gain.
The function \(\mathrm{Impurity}\) measures the uncertainty of the prediction of the class with the highest empirical disctribution \(p_{\cal L}(y)\). If the empirical distribution is very high for one class and very low for the remaining classes, then the impurity is low. We consider the following definitions of impurity:
Definition 35 (Impurity measures)
We define the following three impurity measures that can be used to compute the information gain:
For a comparison of the impurity measures, we plot them for the case of two classes. The horizontal axis indicates the empirical distribution of one of the two classes (class \(y=0\)).

We observe that there are no big differences between the three impurity plots. Gini impurity and entropy increase visibly more steeply from the completely pure class distributions where \(p_{\mathcal{L}}(0)\) is either zero or one.
Stopping Criterion#
Common stopping criterions, that can also be combined, are the following:
Maximum depth is reached: in this case, we should keep track of the recursion level to see whether we exceed a predefined hyperparameter indicating the maximum tree depth.
Minimum number of samples per split: stop if one of the split sets \(\mathcal{L}_0\) or \(\mathcal{L}_1\) contain fewer observations than a predefined threshold.
No significant impurity gain: test after evoking the \(\mathtt{split}\) function if the impurity gain is exceeding a specified threshold.
The stopping criterion is the main property to prohibit overfitting, which is generally associated with a big tree. In addition, pruning strategies exist to remove less significant branches after the training. But this is out of the scope of this section.
Decision Boundary#
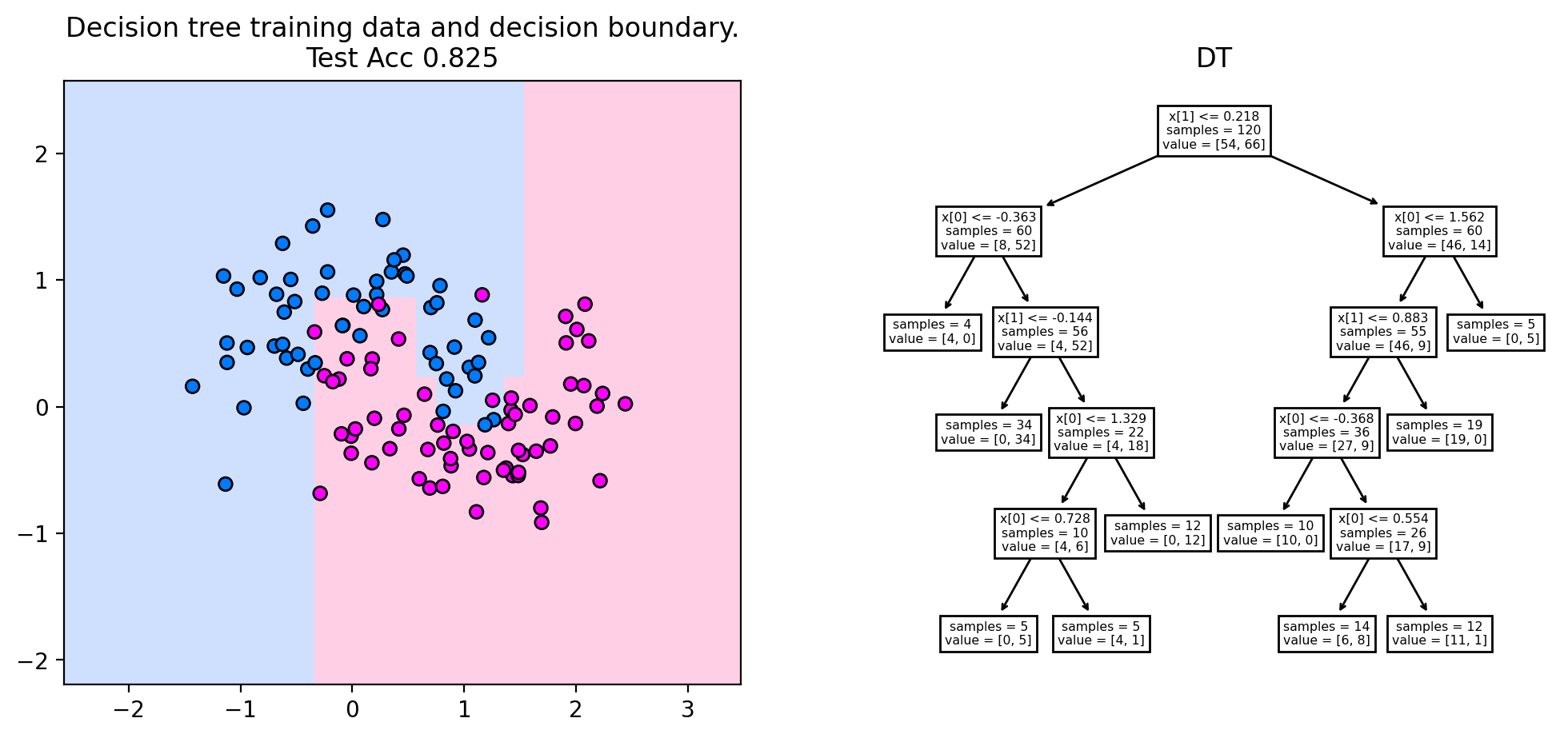
The plot below indicates the decision boundary and the corresponding tree for the two moons dataset, setting the maximum tree depth to five. We observe the typical rectangular decision boundaries of the decision tree, that stem from feature-wise partitioning of the space. Each decision node partitions the feature space in two halves. The root node splits at \(x[1]\leq 0.218\), resulting in a horizontal split that separates roughly the two moons from each other. The next split in the lower horizontal half (for \(x[1]\leq 0.218\)) is a vertical split at \(x[0]\leq 0.363\). The rectangle defined by \(x[1]\leq 0.218\) and \(x[0]\leq 0.363\) is then assigned to the blue class by the prediction node when going twice left in the decision tree. This way, rectangular decision boundaries are created.
from sklearn.inspection import DecisionBoundaryDisplay
from matplotlib.colors import ListedColormap, LinearSegmentedColormap
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.model_selection import train_test_split
import numpy as np
mpl.rcParams['figure.dpi'] = 200
X,y = make_moons(noise=0.3, random_state=0, n_samples=200)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.4, random_state=42
)
fig, axs = plt.subplots(ncols=2, figsize=(12, 5))
cm = ListedColormap(["#a0c3ff", "#ffa1cf"])
cm_points = ListedColormap(["#007bff", "magenta"])
clf = tree.DecisionTreeClassifier(max_depth=5)
y_pred = clf.fit(X_train, y_train)
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="predict",
plot_method="pcolormesh",
shading="auto",
alpha=0.5,
ax=axs[0],
cmap=cm,
)
axs[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, edgecolors="k",cmap = cm_points)
axs[0].set_title(
f"Decision tree training data and decision boundary.\nTest Acc {np.mean(clf.predict(X_test) == y_test)}"
)
ax.axis('scaled')
# Plot tree
tree.plot_tree(clf, filled=False, ax=axs[1], impurity=False)
axs[1].set_title(f"DT")
plt.show()