Normed Vector Spaces
Contents
Normed Vector Spaces#
In the previous section, we introduced vector spaces as algebraic structures that allow addition and scalar multiplication. We have also seen that vectors are geometric objects: their addition and scaling can be visualized by geometric properties. Another geometric property of a vector is the length, which is measured by a norm.
Definition 10
A normed vector space is a vector space \(\mathcal{V}\) with a function \(\lVert\cdot\rVert:\mathcal{V}\rightarrow \mathbb{R}_+\), called norm, satisfying the following properties for all \(\vvec{v},\vvec{w}\in\mathcal{V}\) and \(\alpha\in\mathbb{R}\):
Euclidean Vector Spaces#
A canonical way to measure the length of vectors is the Euclidean norm. This norm returns the lengths of vectors similar to what we would get when we measure the vector with a measure tape.
Example 2
The \(d\)-dimensional Euclidean space is the space of \(\mathbb{R}^d\) with the Euclidean norm:

The image above shows the triangle that is defined over the vector \((v_1,v_2)\). The length of the hypothenuse is defined over the lengths of legs by means of the Pythagorean theorem as:
The Euclidean norm introduces a geometric interpretation of the inner product of two vectors. The inner product is defined by the lengths of the vectors and the cosine of the angle between them.

In Machine Learning, the inner product is often used as a similarity measure between two points. The idea is that two points facing in the same direction have a cosine close to one, and hence a larger inner product than two points looking into distint directions.
Definition 11
Two vectors \(\mathbf{v}\) and \(\mathbf{w}\) are called orthogonal if their inner product is zero \(\mathbf{v}^\top \mathbf{w}=0\).
They are called orthonormal if they are orthogonal and have unit norm \(\lVert \vvec{v}\rVert = \lVert\vvec{w}\rVert =1\).
From the definition follows that if two (nonzero) vectors are orthogonal, then they are at a right angle. The inner product is zero
only if \(\cos\sphericalangle(\vvec{v},\vvec{w})=0\), because the norm is only zero if the vector is the zero vector. For the zero vector, we can’t really talk about an angle between it and another vector, because the zero vector has no direction. The image below shows two orthogonal vectors.

Multiplying with a norm-1 vector has a very important geometric meaning, which is used often in machine learning. Note that any vector \(\mathbf{w}\) can be normalized to a norm-1 vector by dividing with the norm. It’s easy to show that the vector \(\frac{\mathbf{w}}{\lVert \mathbf{w}\rVert}\) has norm 1, because we can pull the scalar \(\frac{1}{\lVert \mathbf{w}\rVert}\) out of the norm due to the homogeneity:
Theorem 2
The inner product of a vector \(\vvec{v}\) and a normalized vector \(\frac{\vvec{w}}{\lVert\vvec{w}\rVert}\) computes the length of the projection \(\vvec{p_v}\) of \(\vvec{v}\) onto \(\vvec{w}\). Using the notation of vectors from the image below, we have

Proof. From the definition of the cosine in a triangle follows that
L_p Vector Spaces#
The Euclidean norm is closely tied to the geometry induced by the Pythagorean theorem. However, the axioms of a norm do not require this geometric structure. They only encode a few fundamental properties of length.
This flexibility allows us to define different norms that measure vectors in fundamentally different ways.
Example 3 (Manhattan (or L1) norm)
The Manhattan norm is defined as:
Both the Euclidean norm and the Manhattan norm follow the same pattern: they combine the coordinates by taking powers, summing them, and applying a root. By allowing the exponent to vary, we obtain a unified family of norms \(L_p\)-norms—which generalize both.
Definition 12 (\(L_p\)-norms)
For \(p \in [1,\infty)\), the \(p\)-norm on \(\mathbb{R}^d\) is defined by
For \(p = \infty\), we define
Proposition 7
For every \(p \in [1,\infty]\), the function \(\lVert \mathbf{v} \rVert_p\) defines a norm on \(\mathbb{R}^d\).
Example 4 (\(L_p\)-balls)
The two-dimensional circles \(\{\vvec{v}\in\mathbb{R}^2\vert \lVert\vvec{v}\rVert_p =1\}\) look as follows:

Matrix Norms#
The idea of measuring the length of a vector can be extended to less canonical vector spaces, like matrices.
Definition 13 (Matrix norms)
We can extend the \(L_p\) vector normes to the element-wise \(L_p\) matrix norms:
Furthermore, we introduce the operator norm
Matrices also have an operation that behaves similar to the inner product, which is defined over the trace of a matrix.
Definition 14 (Trace)
The trace sums the elements on the diagonal of a matrix. Let \(A\in\mathbb{R}^{n\times n}\), then
\(\tr(cA+B)=c\tr(A)+\tr(B)\) (linearity)
\(\tr(A^\top)=\tr(A)\)
\(\tr(ABCD)=\tr(BCDA)=\tr(CDAB)=tr(DABC)\) (cycling property)
The inner vector product can be seen as a special case of the inner product that is defined over the trace. For any vector \(\vvec{v}\in\mathbb{R}^d\) and matrix \(A\in\mathbb{R}^{n\times d}\), we have
The \(L_2\) vector and matrix norms have a binomial formula, that can be derived from the inner product defining the norm:
Orthogonal Matrices#
The abstraction from orthogonal vectors to orthogonal matrices is defined over the orthogonality of the rows and columns of a matrix. If the columns of a matrix \(A\) are orthogonal, then the matrix \(A^\top A\) is diagonal
If, in addition, each column has unit length \(\lVert A_{\cdot i}\rVert =1\), then the columns of \(A\) are orthonormal and the product \(A^\top A\) is equal to the identity matrix
The definition of orthogonal matrices is weirdly different from the properties of the corresponding columns, since a matrix is called orthogonal if the columns are orthonormal and the rows are orthonormal, as indicated below.
Definition 15
A square matrix \(A\in \mathbb{R}^{n\times n}\) is called orthogonal if
Proposition 8
The \(L_2\) vector and matrix norm \(\|\cdot\|_2\) is orthogonal invariant.
Proof. If \(X\) is orthogonal, then \(X^\top X = I\). Hence
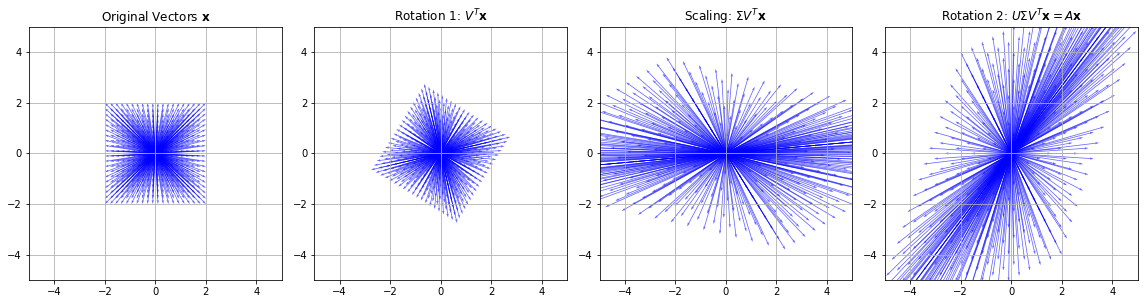
For \(p\in[1,\infty]\) with \(p\neq 2\), the norm \(\|\cdot\|_p\) is in general not orthogonal invariant. Orthogonal invariance gives a nice geometric meaning to orthogonal vectors and matrices: they model a rotation. If we multiply an orthogonal matrix with a vector or matrix, then it doesn’t change the length of that vector in the \(L_2\)-norm. Hence, everything that they can change is the direction of the vector.
In fact, every multiplication of a matrix \(X\) with a vector can be interpreted as a rotation, a scaling and another rotation of that vector. This property is defined by the decomposition of a matrix \(X\) that is given by the Singular Value Decomposition (SVD).
Theorem 3 (SVD)
For every matrix \(X\in\mathbb{R}^{n\times p}\) there exist orthogonal matrices \(U\in\mathbb{R}^{n\times n}, V\in\mathbb{R}^{p\times p}\) and \(\Sigma \in\mathbb{R}^{n\times p}\) such that
\(U^\top U= UU^\top=I_n, V^\top V=VV^\top= I_p\)
\(\Sigma\) is a rectangular diagonal matrix, \(\Sigma_{11}\geq\ldots\geq \Sigma_{kk}\) where \(k=\min\{n,p\}\)
The column vectors \(U_{\cdot s}\) and \(V_{\cdot s}\) are called left and right singular vectors and the values \(\sigma_i=\Sigma_{ii}\) are called singular values \((1\leq i\leq l)\). Let’s have a look how we can compute the SVD in Python.
A = np.random.rand(4,2)
U, σs,Vt = linalg.svd(A)
print(U.shape, σs.shape, Vt.shape)
(4, 4) (2,) (2, 2)
We see that the matrix \(U\) is a \(4\times 4\) matrix, the matrix \(\Sigma\) is given only by the array of singular values and the matrix \(V^\top\) is a \(2\times 2\) matrix. The matrix \(U\) is given as follows:
U
array([[-0.5, 0.7, -0.3, -0.4],
[-0.3, -0.7, -0.4, -0.6],
[-0.5, -0.1, 0.8, -0.2],
[-0.7, -0.1, -0.2, 0.7]])
\(U\) is orthogonal, when we compute \(UU^\top\), then we get the identity matrix (or the numerically computed equivalent of an identity matrix, having values approximately equal to zero outside of the diagonal):
U@U.T
array([[ 1.0e+00, -1.3e-17, 9.7e-17, 6.8e-17],
[-1.3e-17, 1.0e+00, 6.8e-18, -6.3e-17],
[ 9.7e-17, 6.8e-18, 1.0e+00, 1.8e-17],
[ 6.8e-17, -6.3e-17, 1.8e-17, 1.0e+00]])
The middle matrix \(\Sigma\) is given by their diagonal vector. We can model it as a diagonal matrix with the diag operator. Its dimensionality is the minimum or the number of columns and rows of the matrix \(X\), which is two in our case.
np.diag(σs)
array([[1.9, 0. ],
[0. , 0.5]])
If we want to transform \(\Sigma\) into the \(4\times 2\) matrix such that we can compute \(U\Sigma V^\top\), then we need to stack the matrix with zeros.
Σ = np.row_stack( (np.diag(σs),np.zeros((2,2))) )
Σ
array([[1.9, 0. ],
[0. , 0.5],
[0. , 0. ],
[0. , 0. ]])
Now we can compute the reconstruction
U@Σ@Vt, A
(array([[0.9, 0.3],
[0.2, 0.6],
[0.7, 0.6],
[1. , 0.8]]),
array([[0.9, 0.3],
[0.2, 0.6],
[0.7, 0.6],
[1. , 0.8]]))
The SVD can tell us if a matrix is invertible, and we can compute the inverse if we have the SVD.
Proposition 9
A \((n\times n)\) matrix \(A=U\Sigma V^\top\) is invertible if all singular values are larger than zero. The inverse is given by
Proof. We first show that \(A\) is invertible if and only if all singular values are strictly positive.
Since \(U\) and \(V\) are orthogonal, they are invertible, with inverses \(U^{-1}=U^\top\) and \(V^{-1}=V^\top\). Hence
Now \(\Sigma\) is a diagonal matrix, and a diagonal matrix is invertible if and only if all its diagonal entries are nonzero. Therefore, \(\Sigma\) is invertible if and only if
Assume now that all singular values are strictly positive. Then \(\Sigma^{-1}\) exists and is given by
Indeed, using \(V^\top V = I\) and \(UU^\top = I\), we obtain
Similarly,
Thus \(V\Sigma^{-1}U^\top\) is both a left and right inverse of \(A\), so it is the inverse of \(A\). Hence
import numpy as np
import matplotlib.pyplot as plt
# Create a grid of vectors (2D plane)
x = np.linspace(-2, 2, 20)
y = np.linspace(-2, 2, 20)
X, Y = np.meshgrid(x, y)
vectors = np.stack([X.ravel(), Y.ravel()], axis=0)
# Define a matrix A (non-symmetric, non-orthogonal)
A = np.array([[2, 1],
[1, 3]])
# Compute SVD: A = U Σ V^T
U, S, VT = np.linalg.svd(A)
Sigma = np.diag(S)
# Decompose transformations
V = VT.T
rotation1 = V
scaling = Sigma
rotation2 = U
# Apply transformations step-by-step
V_vectors = rotation1 @ vectors
S_vectors = scaling @ V_vectors
U_vectors = rotation2 @ S_vectors # Final result: A @ vectors
# Plotting setup
fig, axs = plt.subplots(1, 4, figsize=(16, 4))
def plot_vectors(ax, vecs, title):
ax.quiver(np.zeros_like(vecs[0]), np.zeros_like(vecs[1]),
vecs[0], vecs[1], angles='xy', scale_units='xy', scale=1,
color='blue', alpha=0.6)
ax.set_xlim(-5, 5)
ax.set_ylim(-5, 5)
ax.set_aspect('equal')
ax.set_title(title)
ax.grid(True)
# Plot each step
plot_vectors(axs[0], vectors, "Original Vectors $\mathbf{x}$")
plot_vectors(axs[1], V_vectors, "Rotation 1: $V^T\mathbf{x}$")
plot_vectors(axs[2], S_vectors, "Scaling: $\Sigma V^T\mathbf{x}$")
plot_vectors(axs[3], U_vectors, "Rotation 2: $U\Sigma V^T\mathbf{x}=A \mathbf{x}$")
plt.tight_layout()
plt.show()